

💙
文章封面来自殘夜 ZANYA-✨
Look me
下面是一些老博客的运维记录,特意留下以备不时只需,现在已经换成NGINX的静态页面了比以前简单了许多^^
BiuBiu
专门开个篇文章记录一下博客升级执行的命令,防止以后忘记了还要现查,比较麻烦
除了记录一些升级操作再记录一些博客服务器宕机的修复,如果后面你遇到和我相似的问题,希望能对你有些参考意义
20220403 Halo Sakura升级
新版本发布咯,halo更新更新,顺便更新下主题,看作者在next分支里修复了不少bug~
仅作记录,更新halo至1.5.1(docker镜像拉取的很慢建议配置镜像加速),更新Sakura主题next分支代码
docker pull halohub/halo:1.5.1
docker stop halo
cp -r ~/.halo ~/.halo.archive
rm -rf ~/.halo/.leveldb
docker run -it -d --name halo1.5.1 -p 1111:1111 -v ~/.halo:/root/.halo --restart=unless-stopped halohub/halo:1.5.1
docker ps docker rm -f halo
主题更新就不多说了代码down下来直接离线包更新即可,就是每次更新后自己改动的小东西都还要重搞一边比较麻烦emm…
20220629 服务器宕机修复
这天刚刚准备安详入眠呢,邮箱短信突然嘟嘟嘟的来了,服务器CPU爆了
放张图感受一下半夜被轰炸的绝望
当时实在太困了,以为是被打了就直接重启大法reboot然后睡了,好家伙第二天起床一看还在崩
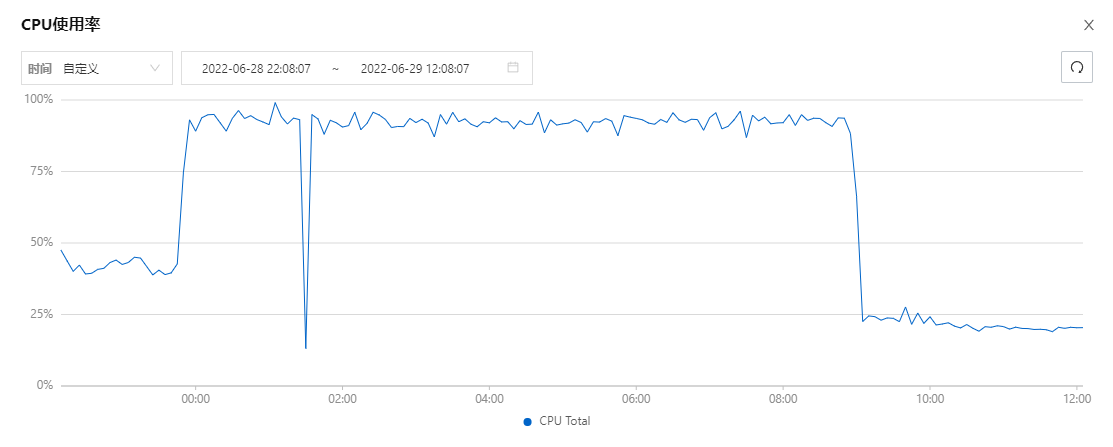
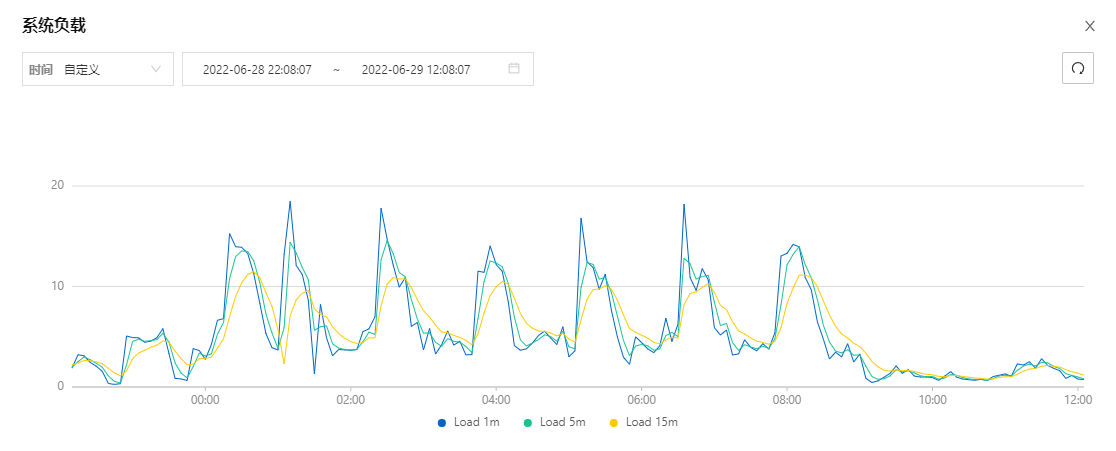
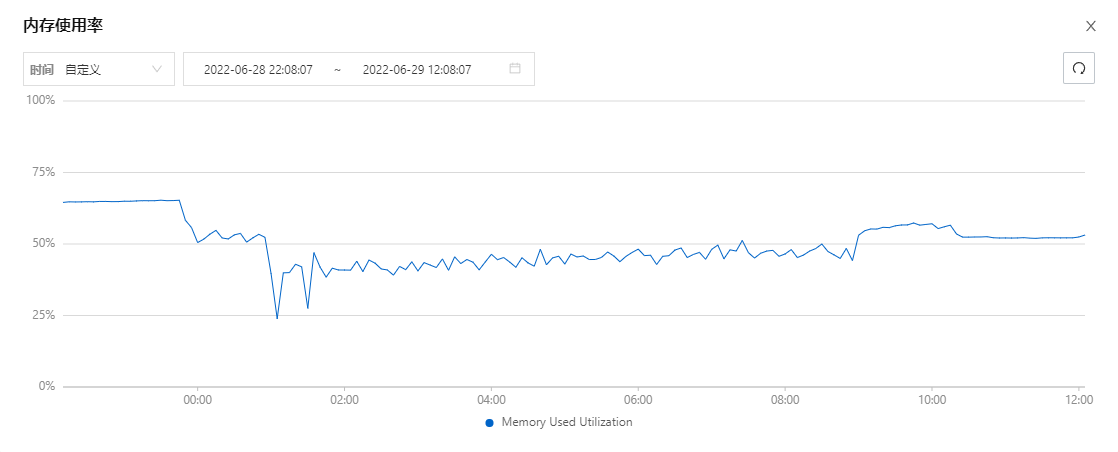
现在复盘起来,看起来确实挺像被打了,公网流量一直都有
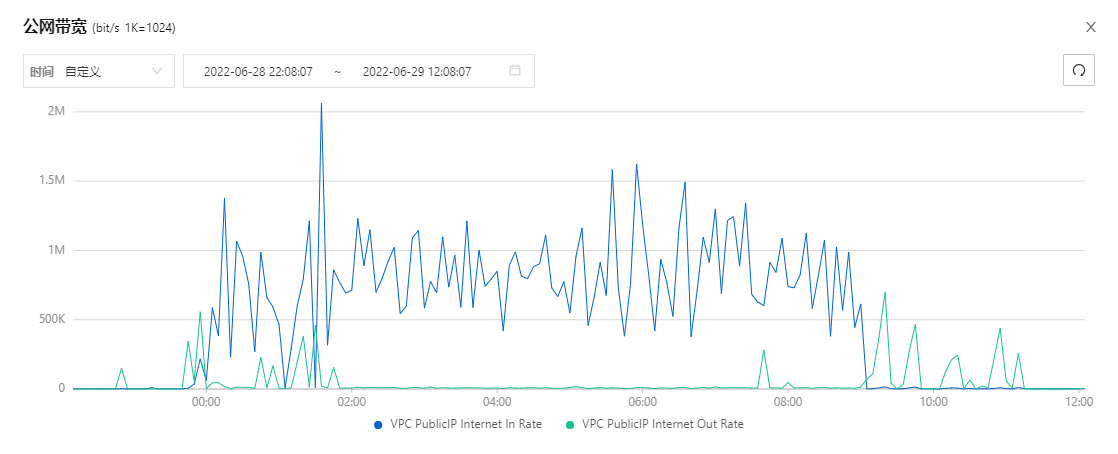
凭着我多年的屁股分析经验,八成是我K3S又嗝屁了,在地铁上手机ssh过去,top看了一下确实,docker跑的一些博客服务都没啥问题,kubectl命令需要等待很长时间才又返回,或者直接报错了
试了试访问博客虽然有点慢还是能刷出来的,ingress和docker是好使的
试了试访问Rancher,不出所料服务暂不可用~
既然Rancher有问题,就检查检查咯
-
查看一下证书管理器的deployment
/usr/local/bin/kubectl get all -n cert-manager检查之后pod都在 没啥问题
-
查看一下Rancher的deployment
/usr/local/bin/kubectl get all -n cattle-system检查之后 好家伙 三个Rancher pod 重启了几百次
这样就说的通了,流量和内存一直忽高忽低是因为拉完镜像创建完容器又杀了重新再拉再启动循环往复…
-
康康Rancher日志
在/var/log/pods下面可以看到对应命名空间下工作负载的POD日志
cd /var/log/pods/cattle-system_rancher-5fd6758ff4-lp6x8_fa5e3dfe-cc95-4fd7-bbdd-f6d5ec663efe/rancher tail -f 290.log日志最后的一些信息
error retrieving resource lock kube-system/cattle-controllers: an error on the server ("apiserver not ready") has prevented the request from succeeding failed to renew lease kube-system/cattle-controllers: timed out waiting for the condition Failed to release lock: resource name may not be empty [FATAL] leaderelection lost for cattle-controllers发现了和Apiserver通信有点问题,选主还失败了
可是为什么会这样,都运行一年多了,怎么突然就有问题呢?
突然想起来,前些天服务满了一年之后续费,因为没啥折扣我降配了,原先的8C现在就2了,还是阉割版
因为我配置太低了…Rancher三个POD启动选主对服务器压力太高了…三个POD互相挤都起不来…然后全部失败又自动拉起成了死循环QAQ
-
穷人就不要开那么多东西了
Rancher缩容 :(
/usr/local/bin/kubectl scale deploy rancher --replicas=1 -n cattle-system
果不其然,Rancher缩成1个之后,服务器就稳定了…
Rancher在Helm安装的时候默认是3个工作负载用做高可用,如果你的机器比较拉,Rancher启动一个工作负载做单机就好啦

20220715 CPU告警修复
和上次类似,Rancher又挂了自动拉没拉起来,短时间自动反复重启导致CPU彪满,手动重启后恢复 (自动重启失败估计是超时时间没咋设置好吧,有空再研究研究,如果Rancher再挂一次我就不把它启动起来了,等需要改东西再拉起来上去操作…
# 先停止 让可怜的机器冷静一下
/usr/local/bin/kubectl scale deploy rancher --replicas=0 -n cattle-system
# 启动
/usr/local/bin/kubectl scale deploy rancher --replicas=1 -n cattle-system