

🐝
文章封面来自殘夜 ZANYA-✨
最近终于去了理想的公司~
是时候继续整理整理过去工作的笔记 share share 了
这篇从最底层的日志采集到展示对ELK(7.5.1)做了完成的部署测试梳理 对生产有一定借鉴意义
介绍顺序是 Filebeat -> Kafka -> Logstash -> ElasticSearch -> Kibana
虽然实践版本有些老 但最关键它不要钱 👻
如果你需要从头搭建白嫖一套日志收集系统 希望本篇文章会对你有用!
Filebeat
测试部署收集日志的beats组件,使用filebeat版本 7.5.1
资源下载
官方文档:Filebeat overview | Filebeat Reference[7.5] | Elastic
部署
mkdir -p /app/logs/filebeat
cd /app
tar -zxvf filebeat-7.5.1-linux-x86_64.tar.gz
mv filebeat-7.5.1-linux-x86_64 filebeat
cd filebeat/
mkdir -p config
cd config
vim filebeat.yml
vim inputs.yml
具体配置如下
配置含义可以参考官方文档
filebeat.yml
filebeat.config.inputs:
enabled: true
path: /app/filebeat/config/inputs.yml
reload.enabled: true
reload.period: 1m
max_procs: 1
output.kafka:
hosts: ["192.168.202.131:9092"]
topic: "%{[topic]}"
logging.to_files: true
logging.files:
path: /app/logs/filebeat/
name: filebeat.log
keepfiles: 2
filebeat.yml 部分配置备注
-
reload
- inputs.yml 调整后 filebeat 可以动态加载
- Live reloading | Filebeat Reference [7.5] | Elastic
-
max_procs
- 同时运行的 cpu 数,建议调低防止日志收集占用机器较多的cpu资源
inputs.yml
- type: log
paths: [/app/logs/nginx/access*.log, /app/nginx/logs/error.log, /app/sunline/nginx/logs/error.log]
encoding: utf-8
fields: {remote_ip: 192.168.202.131, system: test, app: test, topic: NGINX-LOGS, type: nginx,
az: xx}
fields_under_root: true
clean_inactive: 25h
ignore_older: 24h
close_inactive: 10m
close_renamed: false
close_removed: true
close_timeout: 5m
inputs.yml 部分配置备注
- fields
- 增加额外 字段(收集进es)
- fields_under_root
- 增加字段到顶级 而不是二级(类似 json 嵌套 如果设置为false 则json结构类似 “fields”:{“app”: “test”} 而不是 “app”: “test”)
- clean_inactive
- 超过设置时间则会从注册(记录收集的文件和位置信息)表中删除 设置时间必须大于 ignore_older 和 scan_frequency
- ignore_older
- 不会收集 修改时间 超过 设置时间范围的文件
- close_inactive
- 超过时间文件未被修改关闭读取文件句柄,下次检测到文件更新,从记录的最后位置读取
- close_renamed
- 如果文件被重命名(比如进行日志滚动),设置为 true 则关闭收集
- close_removed
- 如果文件被删除,设置为 true 则关闭收集
- close_timeout
- filebeat读取器的最长生命周期,超过则会关闭,再下次读取时重新开始计时
创建启动脚本
cd /app/filebeat
vim filebeat.sh
filebeat.sh
#!/bin/bash
PARAMETER=""
if [ $# -gt 0 ];then
PARAMETER=$*
fi
KEYWORDS="/app/filebeat/filebeat"
gspPID=0
getGspPID(){
pid=`ps -ef|grep $KEYWORDS | grep -v grep | grep -v "filebeat.sh" | awk '{print $2}'`
if [ -n "$pid" ]; then
gspPID=$pid
else
gspPID=0
fi
}
gspShutDown(){
getGspPID
if [ $gspPID -ne 0 ]; then
kill $gspPID
clear
echo "filebeat 已停止"
else
echo "filebeat 没有启动"
fi
}
gspStartup(){
getGspPID
if [ $gspPID -ne 0 ]; then
echo "系统已经启动"
else
chmod 644 /app/filebeat/config/filebeat.yml
nohup nice -n 19 /app/filebeat/filebeat -c /app/filebeat/config/filebeat.yml > /dev/null 2>&1 &
fi
getGspPID
if [ $gspPID -ne 0 ]; then
taskset -cp 0 $gspPID
else
echo "filebeat未启动"
fi
}
clear
if [ "xstart" == "x$1" ]; then
gspStartup
else
if [ "xstop" == "x$1" ]; then
gspShutDown
else
echo "启动指令:filebeat.sh start/stop"
fi
fi
启动filebeat
sh filebeat.sh start
如果需要停止
sh filebeat.sh stop
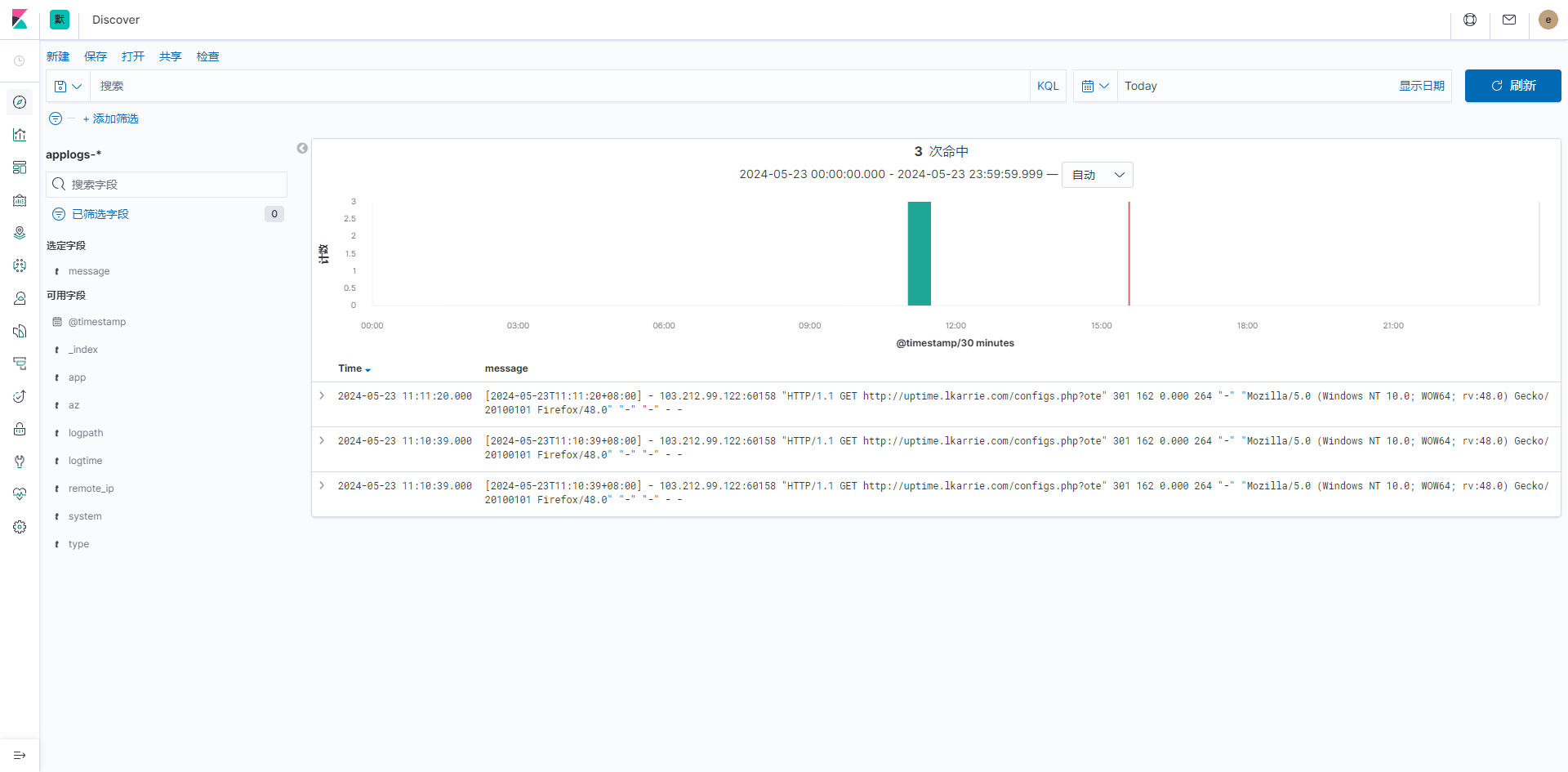
日志收集测试
进行日志收集测试之前,确保已经按照文档完成了 filebeat 和 kafka 的部署
进行NGINX日志收集的测试
根据 filebeat 配置文件,filebeat 收集 /app/logs/nginx/ 下的所有 access*.log
手动创建测试 access log
mkdir -p /app/logs/nginx/
vim /app/logs/nginx/access-test4.log
录入的NGINX日志文件内容如下(关于NGINX 我有另外一篇文章详细记录了相关的内容 NGINX日志也是经过调整后的格式)
[2024-05-24T15:53:06+08:00] - 103.212.99.122:60158 "HTTP/1.1 GET http://uptime.lkarrie.com/configs.php?ote" 301 162 0.000 264 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0" "-" "-" - -
录入成功后检查 filebaet 日志,是否收集了 access-test4.log 文件
cd /app/logs/filebeat
grep Har * | grep test4

filebeat 成功 Harvester 相关文件即正常
上述的检索方式也可以验证 filebeat 是否收集了其他日志文件
补充内容
仅是搭建测试环境,可以跳过这部分内容
实际在收集日志会有多种类型的日志比如 应用的Java日志,NGINX日志,数据库日志,系统日志等,在实践过程中可以按照类型在 inputs.yml 中区分为不同 topic,具体如下(仅供参考
# 收集 JAVA 应用日志
- type: log
paths: [/app/logs/**/*.log]
exclude_files: [^\/app\/logs\/nginx\/.*, ^\/app\/logs\/net-device\/.*]
encoding: utf-8
fields: {remote_ip: 192.168.202.131, system: test, app: test, topic: APP-VM-LOGS, type: app,
az: xx}
fields_under_root: true
multiline.pattern: ^\[
multiline.negate: true
multiline.match: after
clean_inactive: 25h
ignore_older: 24h
close_inactive: 10m
close_renamed: false
close_removed: true
close_timeout: 5m
# 收集 需要进行日志告警的 文本文件
- type: log
paths: [/app/logs/**/*.alert]
encoding: utf-8
fields: {remote_ip: 192.168.202.131, system: test, app: test, topic: LOG_ALERT, type: alert,
az: xx}
fields_under_root: true
multiline.pattern: ^\[
multiline.negate: true
multiline.match: after
clean_inactive: 25h
ignore_older: 24h
close_inactive: 10m
close_renamed: false
close_removed: true
close_timeout: 5m
# 收集系统日志
- type: log
paths: [/var/log/messages, /var/log/sftp.log, /var/named/data/named.run]
encoding: utf-8
fields: {remote_ip: 192.168.202.131, system: test, app: test, topic: SYS-LOGS, type: sys,
az: xx}
fields_under_root: true
clean_inactive: 25h
ignore_older: 24h
close_inactive: 10m
close_renamed: false
close_removed: true
close_timeout: 5m
# 收集 oracle 日志
- type: log
paths: [/grid/grid_base/diag/crs/*/crs/trace/ocssd.trc, /grid/grid_base/diag/crs/*/crs/trace/crsd.trc,
/oracle/diag/rdbms/*/*/trace/alert_*.log]
encoding: utf-8
fields: {remote_ip: 192.168.202.131, system: test, app: test, topic: DB-LOGS, type: oracle,
az: xx}
fields_under_root: true
multiline.pattern: ^[0-9]{4}-[0-9]{2}-[0-9]{2}
multiline.negate: true
multiline.match: after
clean_inactive: 25h
ignore_older: 24h
close_inactive: 10m
close_renamed: false
close_removed: true
close_timeout: 5m
# 收集 postgresql 日志
- type: log
paths: [/pglog/postgresql-*.csv, /pgbak/*/log/bak.log]
encoding: utf-8
fields: {remote_ip: 192.168.202.131, system: test, app: test, topic: DB-LOGS, type: postgresql,
az: xx}
fields_under_root: true
multiline.pattern: ^[0-9]{4}-[0-9]{2}-[0-9]{2}
multiline.negate: true
multiline.match: after
clean_inactive: 25h
ignore_older: 24h
close_inactive: 10m
close_renamed: false
close_removed: true
close_timeout: 5m
另外在线上环境中,通常应用都会对日志进行滚动更新,始终保持本地的日志文件时间在滚动周期内,这样就会产生一个问题,在日志滚动触发的时点会不会产生日志丢失的问题
这里直接说结论
以 logrotate 对大日志文件进行切割为例,日志文件 inode 不会变化的情况下如果进行压缩切割会导致日志丢失
切割方法:
copytruncate:创建日志文件副本并截断原始日志文件(日志文件 inode 不会改变)
create:创建新的日志文件,原文件被mv成旧文件(日志文件 inode 会改变)
场景:
- 当使用copytruncate滚动为gz文件 xxx.log xxx.log.1.gz copytruncate 会导致日志丢失
Logrotate配置
/app/logs/test.log
{
rotate 20
daily
compress
copytruncate
}
- 当使用create滚动为gz文件 xxx.log xxx.log.1.gz copytruncate 日志不会丢失
Logrotate配置
/app/logs/test.log
{
rotate 20
daily
compress
create 644 root root
}
- 当使用copytruncate滚动为普通备份文件 xxx.log xxx.log.1 filebeat 收集 xxx.log* 日志不会丢失
Logrotate配置
/app/logs/test.log
{
rotate 20
daily
copytruncate
}
- 当使用create滚动为普通备份文件 xxx.log xxx.log.1 filebeat 收集 xxx.log* 日志不会丢失
Logrotate配置
/app/logs/test.log
{
rotate 20
daily
create 644 root root
}
Kafka
测试部署收集filebeat推送日志,broker和zookeepr,均部署单节点
测试版本:
-
Kafka 2.12-2.2.0
-
Zookeeper 3.4.13
如果需要使用当前版本的Kafka(例如 Java),客户端版要求 2.2.0
资源下载
下载地址
-
Kafka
-
下载版本:kafka_2.12-2.2.0.tgz
-
Zookeeper
- Index of /dist/zookeeper/zookeeper-3.4.13 (apache.org)
- 下载版本:zookeeper-3.4.13.tar.gz
部署
部署节点
| 部署 | ip | 端口 |
|---|---|---|
| broker | 192.168.202.131 | 9092 |
| zookeeper | 192.168.202.131 | 2181(服务端口)2888(集群内机器通讯使用Leader 和 Follower 之间数据同步使用的端口号,Leader 监听此端口)3888(选举leader端口) |
环境要求
- Jdk 1.8
低版本需要卸载重新安装符合要求的版本(测试虚拟机为 jdk1.7 所以卸载重装
rpm -qa | grep jdk
yum -y remove copy-jdk-configs-3.3-10.el7_5.noarch
yum search java | grep jdk
yum install java-1.8.0-openjdk-devel.x86_64 -y
java -version
准备安装目录、日志目录、存储目录(上传安装包到 /app 目录下
cd /app
tar -zxvf zookeeper-3.4.13.tar.gz
mv zookeeper-3.4.13 zookeeper
rm zookeeper-3.4.13.tar.gz
mkdir -p /app/logs/zookeeper
mkdir -p /app/data/zookeeper
tar -zxvf kafka_2.12-2.2.0.tgz
mv kafka_2.12-2.2.0 kafka
rm kafka_2.12-2.2.0.tgz
mkdir /app/logs/kafka
mkdir /app/data/kafka
Zookeeper部署
cd /app/zookeeper/config
vim zoo.cfg
单节点 zoo.cfg 配置 如下
#zk服务端与客户端心跳时间
tickTime=2000
#数据目录
dataDir=/app/data/zookeeper/
#服务端口
clientPort=2181
修改日志配 调整日志到对应目录
# Define some default values that can be overridden by system properties
zookeeper.root.logger=INFO, CONSOLE
zookeeper.console.threshold=INFO
zookeeper.log.dir=/app/logs/zookeeper
zookeeper.log.file=zookeeper.log
zookeeper.log.threshold=DEBUG
zookeeper.tracelog.dir=/app/logs/zookeeper
zookeeper.tracelog.file=zookeeper_trace.log
#
# ZooKeeper Logging Configuration
#
# Format is "<default threshold> (, <appender>)+
启动
cd /app/zookeeper
# 使用默认JVM参数启动
./bin/zkServer.sh start
补充内容
常用命令
#启动(默认识别 conf/zoo.cfg)
./bin/zkServer.sh start
#停止
./bin/zkServer.sh stop
#重启
./bin/zkServer.sh restart
#指定配置文件启动
./bin/zkServer.sh --config zoo.cfg的目录 {start,stop,restart,status,upgrade,print-cmd,start-foreground}
如果需要调整zookeeper堆内存
# 在 conf 目录下设置JVM参数
cd /app/zookeeper/conf
vim java.env
# 调整完成后重启 zookeeper
# 可以通过 ps -aux | grep zookeeper 或者 jmap -heap pid 查看堆内存参数
java.env
export JVMFLAGS="-Xmx2g"
export JVMFLAGS="-Xms1g $JVMFLAGS"
如果尝试集群部署,zookeeper 配置如下(仅供参考
#zk服务端与客户端心跳时间
tickTime=2000
#leader和follower初始化通信时限
initLimit=10
#leader和follower通信时限
syncLimit=5
#数据目录
dataDir=/app/data/zookeeper/
#服务端口
clientPort=2181
#单机部署 不需要配置
#集群模式,server地址
server.1=1.1.1.1:2888:3888
server.2=1.1.1.2:2888:3888
server.3=1.1.1.3:2888:3888
#四字白名单
#4lw.commands.whitelist=*
#跳过acl(acl配置错误后可临时开启修改acl)
#skipAcl=true
使用集群部署,需要分别在所有zookeeper节点额外创建myid
#zookeeper 节点1 机器
echo 1 > /app/data/zookeeper/myid
#zookeeper 节点2 机器
echo 2 > /app/data/zookeeper/myid
#zookeeper 节点3 机器
echo 3 > /app/data/zookeeper/myid
Kafka部署
cd /app/kafka/config
vim server.properties
broker配置
#broker在集群中的唯一标识
#每台broker需不同 可以分别设置 0 1 2 3 ...
broker.id=0
#server暴露服务端口
listeners=PLAINTEXT://192.168.202.131:9092
advertised.listeners=PLAINTEXT://192.168.202.131:9092
#根据机器cpu调整
num.network.threads=3
#根据机器cpu调整
num.io.threads=8
#socket发送缓存区大小限制
socket.send.buffer.bytes=102400
#socket接收缓冲区大小限制
socket.receive.buffer.bytes=102400
#socket可请求消息体最大限制
socket.request.max.bytes=104857600
#kafka存放消息路径
log.dirs=/app/data/kafka
#默认建立topic分区数量
#建议topic分区数与kafka节点数一致
num.partitions=1
#kafka宕机后,恢复数据线程数量设置;每个目录占用的线程数量
num.recovery.threads.per.data.dir=1
#topic副本默认数量
#建议topic副本数大于等于3
offsets.topic.replication.factor=1
#事务消息副本数量
transaction.state.log.replication.factor=1
#事务消息副本处于isr的最小数量
transaction.state.log.min.isr=1
# 数据文件保存时间
log.retention.hours=168
# 日志分段阈值 1G
log.segment.bytes=1073741824
# 数据文件扫描间隔,过期时间文件进行删除
log.retention.check.interval.ms=300000
# zookeeper配置
zookeeper.connect=localhost:2181
# zookeeper连接超时时间
zookeeper.connection.timeout.ms=6000
# 消费者组重平衡初始化延迟时间
group.initial.rebalance.delay.ms=0
日志目录修改
sed -i -e 's/${kafka.logs.dir}/\/app\/logs\/kafka/g' log4j.properties
启动和停止
#启动
nohup ./bin/kafka-server-start.sh ./config/server.properties 2>&1 &
# Java 堆内存 按需调整 在脚本 kafka-server-start.sh 内
# 默认 export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
#停止
./bin/kafka0server-stop.sh
配置开机自启,zookeepr同样可参考配置开机自启动
crontab -e
@reboot sh /app/kafka/bin/kafka-server-start.sh /app/kafka/config/server.properties
补充内容
补充一份我实际在生产环境中收集日志信息所使用的配置(仅供参考
kafka-server-start.sh 内 jvm 参数
export KAFKA_HEAP_OPTS="-Xmx12G -Xms12G -XX:MaxDirectMemorySize=8G"
broker
broker.id=0
listeners=PLAINTEXT://1.1.1.1:9092
advertised.listeners=PLAINTEXT://1.1.1.1:9092
listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
num.network.threads=16
num.io.threads=32
socket.send.buffer.bytes=10485760
socket.receive.buffer.bytes=10485760
socket.request.max.bytes=104857600
log.dirs=/app/data/kafka
num.partitions=3
auto.create.topics.enable=false
delete.topic.enable=false
offsets.topic.replication.factor=7
transaction.state.log.replication.factor=7
transaction.state.log.min.isr=2
log.retention.hours=24
log.segment.bytes=1073741824
log.retention.check.interval.ms=60000
zookeeper.connect=1.1.1.1:2181,1.1.1.2:2181,1.1.1.3:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
补充常用的命令
# 创建topic
./bin/kafka-topics.sh --bootstrap-server 192.168.202.131:9092 --create --topic demo --partition 7 --replication-factor 2
# 查看topic详情
./bin/kafka-topics.sh --bootstrap-server 192.168.202.131:9092 --topic demo --describe
# 查看topic列表
./bin/kafka-topics.sh --bootstrap-server 192.168.202.131:9092 --list
# 扩容分区(分区只能扩容,不能缩容)
./bin/kafka-topics.sh --bootstrap-server 192.168.202.131:9092 --alter --topic demo --partitions 12
# 修改单个topic存放数据时间(如果单天数据量过大,可能需要临时修改,单位ms)
./bin/kafka-config.sh --zookeeper 192.168.202.131:2181 --entiy-type topics --entiy-name topic-xxxx --alter --add-config retention.ms=86400000
# group相关
# 创建group(一般不需要手动创建)
./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.202.131:9092 --topic topic-xxx --consumer-property group.id=group_mytes
# 查看group详情
./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.202.131:9092 --group logstash-nginx --describe
# 查看group列表
./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.202.131:9092 --list
# 删除group
./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.202.131:9092 --group logstash-nginx --delete
验证命令
# 如果ELK整体搭建完毕 并没有自动创建日志索引 需要按顺序依次确认:
# 1. filebeat 是否收集到相关日志
# 2. filebeat 是否自动创建 kafka topic
# 3. 自动创建的 topic 是否实际存在消息
# 4. logstash 消费组 是否消费了消息(offset、lag)
# 查看 topic
./bin/kafka-topics.sh --describe --topic NGINX-LOGS --bootstrap-server 192.168.202.131:9092
# 输出内容(展示了topic分区和副本的相关信息
Topic:NGINX-LOGS PartitionCount:1 ReplicationFactor:1 Configs:segment.bytes=1073741824
Topic: NGINX-LOGS Partition: 0 Leader: 0 Replicas: 0 Isr: 0
# 查看有没有消息 从第一条消息开始查看
./bin/kafka-console-consumer.sh --bootstrap-server 192.168.202.131:9092 --topic NGINX-LOGS --from-beginning
# 输出内容为 json 格式的消息
# 查看消费者组 消费情况
./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.202.131:9092 --describe --group logstash-nginx
# 输出(offset相同则则消息均被消费 LAG表示落后未被消费的消息
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
NGINX-LOGS 0 8 8 0 logstash-0-f0b8637b-26f6-4f23-ab80-f298f63aca6f /192.168.202.131 logstash-0
Logstash
测试部署消费Kafka日志消息,推送到ES集群的 Logstash,使用版本 7.5.1
资源下载
官方文档:Installing Logstash | Logstash Reference [7.5] | Elastic
部署
cd /app/
tar -zxvf logstash-7.5.1.tar.gz
mv logstash-7.5.1 logstash
cd logstash/config
mkdir pipeline
mv logstash.yml logstash.yml.bk
vim logstash.yml
logstash.yml
pipeline.workers: 5
pipeline.batch.size: 500
pipeline.batch.delay: 10
http.host: "0.0.0.0"
path.config: /app/logstash/config/pipeline
config.reload.automatic: true
config.reload.interval: 60s
xpack.monitoring.enabled: true
xpack.monitoring.elasticsearch.username: logstash_system
xpack.monitoring.elasticsearch.password: "123456"
xpack.monitoring.elasticsearch.hosts: ["http://192.168.202.131:9200","http://192.168.202.131:9201","http://192.168.202.131:9202"]
继续创建管道配置
vim pipeline/logstash.conf
logstash.conf
input {
kafka {
bootstrap_servers => ["192.168.202.131:9092"]
group_id => "logstash-nginx"
auto_offset_reset => "latest"
consumer_threads => 2
topics => ["NGINX-LOGS"]
codec => "json"
}
}
filter {
if [log][file][path] =~ /\/access-.*\.log$/ {
grok {
match => {"message" => "\[%{TIMESTAMP_ISO8601:logtime}\]"}
}
if [logtime] {
date {
match => [ "logtime", "ISO8601" ]
timezone => "Asia/Shanghai"
}
mutate {
gsub => ["logtime", "T[0-9]{2}:[0-9]{2}:[0-9]{2}\+[0-9]{2}:[0-9]{2}", ""]
gsub => ["logtime", "[-]", "."]
copy => {"[log][file][path]" => "logpath"}
remove_field => ["input", "host", "agent", "ecs", "topic", "@version", "log"]
}
fingerprint {
source => ["remote_ip", "logpath", "message"]
target => "[@metadata][fingerprint]"
method => "MD5"
key => "Log Deduplicate"
base64encode => true
concatenate_sources => true
}
} else {
drop {}
}
} else if [log][file][path] =~ /\/error\.log$/ {
grok {
pattern_definitions => { "ERROR_TIME" => "%{YEAR}/%{MONTHNUM}/%{MONTHDAY} %{TIME}" }
match => {"message" => "%{ERROR_TIME:logtime}"}
}
if [logtime] {
date {
match => [ "logtime", "yyyy/MM/dd HH:mm:ss" ]
timezone => "Asia/Shanghai"
}
mutate {
gsub => ["logtime", " [0-9]{2}:[0-9]{2}:[0-9]{2}", ""]
gsub => ["logtime", "[/]", "."]
copy => {"[log][file][path]" => "logpath"}
remove_field => ["input", "host", "agent", "ecs", "topic", "@version", "log"]
}
fingerprint {
source => ["remote_ip", "logpath", "message"]
target => "[@metadata][fingerprint]"
method => "MD5"
key => "Log Deduplicate"
base64encode => true
concatenate_sources => true
}
} else {
drop {}
}
} else {
drop {}
}
}
output {
elasticsearch {
hosts => ["http://192.168.202.131:9200","http://192.168.202.131:9201","http://192.168.202.131:9202"]
document_id => "%{[@metadata][fingerprint]}"
index => "applogs-%{system}-%{logtime}"
template_name => "applogs"
user => "logstash_writer"
password => "123456"
}
}
创建启停脚本
cd /app/logstash/bin
vim start.sh
vim stop.sh
start.sh
nohup /app/logstash/bin/logstash 2>&1 &
stop.sh
pid=`ps -ef | grep logstash | awk '{print $2}'`
kill -15 $pid
启动
sh start.sh
检查日志
cd /app/logstash/logs
ElasticSearch
测试部署收集日志的文档数据库,使用单机多进程的方式,模拟3节点ES集群
模拟节点信息和角色规划如下
| 节点 | IP | 端口 | 主节点 | 数据节点 |
|---|---|---|---|---|
| 模拟节点1 | 192.168.202.131 | 9200,9300 | TRUE | FALSE |
| 模拟节点2 | 192.168.202.131 | 9201,9301 | TRUE | TRUE |
| 模拟节点3 | 192.168.202.131 | 9202,9302 | TRUE | TRUE |
注意:
由于测试虚机资源有限,这里就不在模拟仅是协调角色(node.master:false,node.data:false)的ES节点
生产ES集群建议,主节点、协调节点、数据节点,均需要单独机器部署
资源下载
下载地址:Elasticsearch 7.5.1 | Elastic
官方文档:Getting started with Elasticsearch | Elasticsearch Guide [7.5] | Elastic
集群配置参数:Important discovery and cluster formation settings | Elasticsearch Guide [7.5] | Elastic
配置中gateway参数:Local Gateway | Elasticsearch Guide [7.5] | Elastic
部署
前置操作(root执行)
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
vim /etc/security/limits.conf
# 添加如下内容
* soft nofile 65536
* hard nofile 65536
* soft memlock unlimited
* hard memlock unlimited
# 退出重新登录
# 验证
ulimit -Hn
ulimit -Sn
vim /etc/sysctl.conf
vm.max_map_count=655360
sudo sysctl -p
# 单机三个安装目录模拟三节点分别部署ES (ms表示master)
tar -zxvf elasticsearch-7.5.1-linux-x86_64.tar.gz
mv elasticsearch-7.5.1 elasticsearch-ms1
tar -zxvf elasticsearch-7.5.1-linux-x86_64.tar.gz
mv elasticsearch-7.5.1 elasticsearch-ms2
tar -zxvf elasticsearch-7.5.1-linux-x86_64.tar.gz
mv elasticsearch-7.5.1 elasticsearch-ms3
# 分别创建对应 日志和数据目录
mkdir -p /app/data/elasticsearch-ms1
mkdir -p /app/logs/elasticsearch-ms1
mkdir -p /app/data/elasticsearch-ms2
mkdir -p /app/logs/elasticsearch-ms2
mkdir -p /app/data/elasticsearch-ms3
mkdir -p /app/logs/elasticsearch-ms3
# 增加 es 运行用户
sudo adduser elasticsearch
sudo chown -R elasticsearch:elasticsearch /app/elasticsearch*
sudo chown -R elasticsearch:elasticsearch /app/data/elasticsearch*
sudo chown -R elasticsearch:elasticsearch /app/logs/elasticsearch*
su elasticsearch
部署 模拟节点1
切换用户后,进行配置调整
cd /app/elasticsearch-ms1/config/
vim jvm.options
jvm.options
# 模拟节点 调整为小堆内存
-Xms512m
-Xmx512m
## GC configuration
# 不使用CMSGC 注释CMSGC
#-XX:+UseConcMarkSweepGC
#-XX:CMSInitiatingOccupancyFraction=75
#-XX:+UseCMSInitiatingOccupancyOnly
## G1GC Configuration
# NOTE: G1GC is only supported on JDK version 10 or later.
# To use G1GC uncomment the lines below.
# 10-:-XX:-UseConcMarkSweepGC
# 10-:-XX:-UseCMSInitiatingOccupancyOnly
# 放开默认注释 使用G1GC垃圾回收
# 对于大的堆内存需要使用G1GC
# 生产也是如此
10-:-XX:+UseG1GC
10-:-XX:G1ReservePercent=25
10-:-XX:InitiatingHeapOccupancyPercent=30
# 下面的均为默认配置 个人在使用中没有在进行过调整
## JVM temporary directory
-Djava.io.tmpdir=${ES_TMPDIR}
## heap dumps
# generate a heap dump when an allocation from the Java heap fails
# heap dumps are created in the working directory of the JVM
-XX:+HeapDumpOnOutOfMemoryError
# specify an alternative path for heap dumps; ensure the directory exists and
# has sufficient space
-XX:HeapDumpPath=data
# specify an alternative path for JVM fatal error logs
-XX:ErrorFile=logs/hs_err_pid%p.log
## JDK 8 GC logging
8:-XX:+PrintGCDetails
8:-XX:+PrintGCDateStamps
8:-XX:+PrintTenuringDistribution
8:-XX:+PrintGCApplicationStoppedTime
8:-Xloggc:logs/gc.log
8:-XX:+UseGCLogFileRotation
8:-XX:NumberOfGCLogFiles=32
8:-XX:GCLogFileSize=64m
# JDK 9+ GC logging
9-:-Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m
创建ES集群传输加密证书
cd /app/elasticsearch-ms1
# 创建CA证书
/app/elasticsearch-ms1/bin/elasticsearch-certutil ca --days 99999
# 检查证书有效期
openssl pkcs12 -in elastic-stack-ca.p12 -nodes | openssl x509 -noout -enddate
# 创建私钥证书
/app/elasticsearch-ms1/bin/elasticsearch-certutil cert --ca elastic-stack-ca.p12 --days 99999
# 复制证书到 ms2 ms3
cd /app/elasticsearch-ms2/config
cp /app/elasticsearch-ms1/config/elastic-* .
cd /app/elasticsearch-ms3/config
cp /app/elasticsearch-ms1/config/elastic-* .
调整 ES 配置
vim elasticsearch.yml
elasticsearch.yml
# 单机模拟部署需要配置 运行一台机器运行多个ES进程
node.max_local_storage_nodes: 3
# 指定集群名称
cluster.name: es-cluster
# 指定节点名称
node.name: ms1
# 数据目录
path.data: /app/data/elasticsearch-ms1
# 日志目录
path.logs: /app/logs/elasticsearch-ms1
network.host: 0.0.0.0
http.port: 9200
# 集群发现
# 设置所有主节点IP
discovery.seed_hosts: ["192.168.202.131:9300","192.168.202.131:9301","192.168.202.131:9302"]
# Master角色的节点 node.name 的名称
cluster.initial_master_nodes: ["ms1","ms2","ms3"]
bootstrap.memory_lock: true
# 网关信息 需要根据实际的 ES集群规划 进行调整
# 初次部署 不满足相关 expected 集群状态则为 RAD
# 期望主节点数
gateway.expected_master_nodes: 3
# 期望数据节点数
gateway.expected_data_nodes: 2
gateway.recover_after_time: 5m
# 集群恢复所需 最少 master 节点
gateway.recover_after_master_nodes: 2
# 集群恢复所需 最少 data 节点
gateway.recover_after_data_nodes: 1
bootstrap.system_call_filter: false
http.cors.enabled: true
http.cors.allow-origin: "*"
http.max_content_length: 100mb
#tcp端口
transport.tcp.port: 9300
transport.tcp.compress: true
# 当 node.master: true node.data: false 是当前节点仅为主节点
# 当 node.master: false node.data: true 是当前节点仅为数据节点
# 当 node.master: false node.data: false 是当前节点仅为协调节点
# 生产环境中绝对不能使master也可以作为数据节点
# 当 node.master: true node.data: true 是当前节点为主节点和数据节点
#声明是master节点
node.master: true
#声明是数据节点
node.data: false
# 集群加密传输
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: /app/elasticsearch-ms1/config/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /app/elasticsearch-ms1/config/elastic-certificates.p12
thread_pool.write.queue_size: 5000
#缓存清理配置
indices.fielddata.cache.size: 30%
创建启动脚本
cd /app/elasticsearch-ms1/config/
vim start.sh
vim stop.sh
start.sh
/app/elasticsearch-ms1/bin/elasticsearch -d
stop.sh
jps | grep Elasticsearch | awk '{print $1}' | xargs kill -15
启动 ES 模拟节点1
sh start.sh
部署 模拟节点2
参考部署模拟节点1,下面仅附相关conf配置
jvm.options 与 模拟节点1 相同
elasticsearch.yml
node.max_local_storage_nodes: 3
cluster.name: es-cluster
node.name: ms2
path.data: /app/data/elasticsearch-ms2
path.logs: /app/logs/elasticsearch-ms2
network.host: 0.0.0.0
http.port: 9201
discovery.seed_hosts: ["192.168.202.131:9300","192.168.202.131:9301","192.168.202.131:9302"]
cluster.initial_master_nodes: ["ms1","ms2","ms3"]
bootstrap.memory_lock: true
gateway.expected_master_nodes: 3
gateway.expected_data_nodes: 2
gateway.recover_after_time: 5m
gateway.recover_after_master_nodes: 2
gateway.recover_after_data_nodes: 1
bootstrap.system_call_filter: false
http.cors.enabled: true
http.cors.allow-origin: "*"
http.max_content_length: 100mb
transport.tcp.port: 9301
transport.tcp.compress: true
node.master: true
node.data: true
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: /app/elasticsearch-ms2/config/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /app/elasticsearch-ms2/config/elastic-certificates.p12
thread_pool.write.queue_size: 5000
indices.fielddata.cache.size: 30%
部署 模拟节点3
参考部署模拟节点1,下面仅附相关conf配置
jvm.options 与 模拟节点1 相比 仅堆内存设置不同
-Xms1g
-Xmx1g
elasticsearch.yml
node.max_local_storage_nodes: 3
cluster.name: es-cluster
node.name: ms3
path.data: /app/data/elasticsearch-ms3
path.logs: /app/logs/elasticsearch-ms3
network.host: 0.0.0.0
http.port: 9202
discovery.seed_hosts: ["192.168.202.131:9300","192.168.202.131:9301","192.168.202.131:9302"]
cluster.initial_master_nodes: ["ms1","ms2","ms3"]
bootstrap.memory_lock: true
gateway.expected_master_nodes: 3
gateway.expected_data_nodes: 2
gateway.recover_after_time: 5m
gateway.recover_after_master_nodes: 2
gateway.recover_after_data_nodes: 1
bootstrap.system_call_filter: false
http.cors.enabled: true
http.cors.allow-origin: "*"
http.max_content_length: 100mb
transport.tcp.port: 9302
transport.tcp.compress: true
node.master: true
node.data: true
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: /app/elasticsearch-ms3/config/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /app/elasticsearch-ms3/config/elastic-certificates.p12
thread_pool.write.queue_size: 5000
indices.fielddata.cache.size: 30%
修改用户密码
三台模拟节点完全启动后,修改所有 ES 用户密码
此时如果集群异常,会有RAD状态提示,这时是无法进行操作修改密码的
cd /app/elasticsearch-ms1
bin/elasticsearch-setup-passwords interactive
# 按用户依次输入密码
# 测试建议保持一致 123456 即 重置所有用户密码为 123456
补充内容
ES 对堆内存的要求比较铭感
所有角色的ES节点堆内存设置 不能超过虚拟机的实际内存的一半且不能超过 30G
我在实际生产使用中
主节点和协调节点 为 16C 32G 服务器 所以堆内存设置为 16G
数据节点为 32C 64G 服务器 所以堆内存设置为 30G
附一份 生产 ES master 角色 jvm.options 配置(仅供参考
jvm.option
## JVM configuration
################################################################
## IMPORTANT: JVM heap size
################################################################
##
## You should always set the min and max JVM heap
## size to the same value. For example, to set
## the heap to 4 GB, set:
##
## -Xms4g
## -Xmx4g
##
## See https://www.elastic.co/guide/en/elasticsearch/reference/current/heap-size.html
## for more information
##
################################################################
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms16g
-Xmx16g
################################################################
## Expert settings
################################################################
##
## All settings below this section are considered
## expert settings. Don't tamper with them unless
## you understand what you are doing
##
################################################################
## GC configuration
#-XX:+UseConcMarkSweepGC
#-XX:CMSInitiatingOccupancyFraction=75
#-XX:+UseCMSInitiatingOccupancyOnly
## G1GC Configuration
# NOTE: G1GC is only supported on JDK version 10 or later.
# To use G1GC uncomment the lines below.
# 10-:-XX:-UseConcMarkSweepGC
# 10-:-XX:-UseCMSInitiatingOccupancyOnly
10-:-XX:+UseG1GC
10-:-XX:G1ReservePercent=25
10-:-XX:InitiatingHeapOccupancyPercent=30
## JVM temporary directory
-Djava.io.tmpdir=${ES_TMPDIR}
## heap dumps
# generate a heap dump when an allocation from the Java heap fails
# heap dumps are created in the working directory of the JVM
-XX:+HeapDumpOnOutOfMemoryError
# specify an alternative path for heap dumps; ensure the directory exists and
# has sufficient space
-XX:HeapDumpPath=data
# specify an alternative path for JVM fatal error logs
-XX:ErrorFile=logs/hs_err_pid%p.log
## JDK 8 GC logging
8:-XX:+PrintGCDetails
8:-XX:+PrintGCDateStamps
8:-XX:+PrintTenuringDistribution
8:-XX:+PrintGCApplicationStoppedTime
8:-Xloggc:logs/gc.log
8:-XX:+UseGCLogFileRotation
8:-XX:NumberOfGCLogFiles=32
8:-XX:GCLogFileSize=64m
# JDK 9+ GC logging
9-:-Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m
附一份 ES master 节点配置(仅供参考
elasticsearch.yml
#指定集群名称
cluster.name: xxx-cluster
#指定节点名称
node.name: xxx01
#数据目录
path.data: /app/data
path.logs: /app/logs
network.host: 0.0.0.0
http.port: 9200
#集群发现
discovery.seed_hosts: ["1.1.1.1","1.1.1.2","1.1.1.3"]
#设置符合主节点的主机名,引导启动集群
cluster.initial_master_nodes: ["xxx01","xxx02","xxx03"]
bootstrap.memory_lock: true
#网关信息
gateway.expected_master_nodes: 2
gateway.expected_data_nodes: 3
gateway.recover_after_time: 5m
gateway.recover_after_master_nodes: 2
gateway.recover_after_data_nodes: 3
bootstrap.system_call_filter: false
http.cors.enabled: true
http.cors.allow-origin: "*"
http.max_content_length: 100mb
#tcp端口
transport.tcp.port: 9300
transport.tcp.compress: true
#声明是 master 节点
node.master: true
#声明是 data 节点
node.data: false
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: /app/elasticsearch/config/cert/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /app/elasticsearch/config/cert/elastic-certificates.p12
thread_pool.write.queue_size: 5000
path.repo: ["/app/elasticsearch/repository3/snapshot","/app/elasticsearch/repository5/snapshot","/app/elasticsearch/repository/snapshot"]
#缓存清理配置
indices.fielddata.cache.size: 30%
集群运维
见 Kibana 部分的 常见集群管理场景
对象存储
创建Minio 仓库
# TLS 可选
# 配置自签证书 es 无法验证存储库
# PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
mkdir -p ${HOME}/.minio/certs
cd ${HOME}/.minio/certs
openssl req -x509 -newkey rsa:4096 -days 365 -nodes -keyout ca-key.pem -out ca-cert.pem -subj "/C=CN/ST=Shanghai/L=Shanghai/O=Education/OU=Education/CN=*.ca.com/emailAddress=test@email.com"
openssl req -newkey rsa:4096 -nodes -keyout private.key -out csr.pem -subj "/C=CN/ST=Shanghai/L=Shanghai/O=TEST1/OU=TEST2/CN=*.server.com/emailAddress=test@email.com"
cat > ./server-ext.cnf << EOF
subjectAltName=DNS:test.minio.com
EOF
openssl x509 -req -in csr.pem -days 3650 -CA ca-cert.pem -CAkey ca-key.pem -CAcreateserial -out public.crt -extfile server-ext.cnf
cat >> /etc/hosts << EOF
192.168.202.131 test.minio.com
EOF
# Minio 测试单节点部署
mkdir -p /app/data/minio
mkdir -p /app/minio
cd /app/minio
wget https://dl.min.io/server/minio/release/linux-amd64/archive/minio.RELEASE.2023-10-14T05-17-22Z
mv minio.RELEASE.2023-10-14T05-17-22Z minio
chmod +x minio
nohup /app/minio/minio server /app/data/minio --console-address ":9001" 2>&1 &
# 测试使用默认minio账号密码
minioadmin / minioadmin
# mc 创建桶 策略 用户
# https://min.io/docs/minio/linux/reference/minio-mc.html
cd /app/minio
wget https://dl.min.io/client/mc/release/linux-amd64/archive/mc.RELEASE.2023-10-14T01-57-03Z
mv mc.RELEASE.2023-10-14T01-57-03Z mc
cat >/tmp/es-rw.json << EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws:s3:::es-s3/*"
]
}
]
}
EOF
./mc alias set minio http://192.168.202.131:9000
./mc mb minio/es-s3
./mc admin policy create minio es-rw /tmp/es-rw.json
./mc admin user add minio esuser
esuser / esuseradmin
./mc admin policy attach minio es-rw --user esuser
./mc admin user svcacct add minio esuser
# 获取测试密钥
Access Key: 6AAB05L0AHCP1YT4UM0Z
Secret Key: WriVttuEUvHtx5V7gbQo+wpUeP3sJeiUUNq0ga4a
Expiration: no-expiry
创建ES S3仓库
上传插件压缩包到所有es节点 /tmp 目录下,插件包名称 repository-s3-7.5.1.zip
在所有es节点上安装插件包
# 查看已经安装插件包
/app/elasticsearch-ms1/bin/elasticsearch-plugin list
# 安装s3存储插件包
/app/elasticsearch-ms1/bin/elasticsearch-plugin install file:///tmp/repository-s3-7.5.1.zip
# 查看是否已经安装
/app/elasticsearch-ms1/bin/elasticsearch-plugin list
在节点执行以下命令,关闭索引自动迁移
# 禁用分片自动分配
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": "none"
}
}
# 执行同步刷新可加快分片快速恢复
POST _flush/synced
滚动重启所有es节点(重启顺序 data core master)
cd /app/elasticsearch-ms1/bin/
# 停止
./stop.sh
# 查看是否完全停止
ps -ef | grep elasticsearch
# 启动
./start.sh
# kibana查看集群节点是否正常
GET _cat/node
# kibana查看集群健康状态
GET _cat/health
开启所有分片自动分配
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": "all"
}
}
测试网络联通性
ping s3.test.com
telnet s3.test.com 443
增加认证
# 所有节点增加默认 client 密钥
/app/elasticsearch-ms1/bin/elasticsearch-keystore add s3.client.default.access_key
/app/elasticsearch-ms1/bin/elasticsearch-keystore add s3.client.default.secret_key
/app/elasticsearch-ms2/bin/elasticsearch-keystore add s3.client.default.access_key
/app/elasticsearch-ms2/bin/elasticsearch-keystore add s3.client.default.secret_key
/app/elasticsearch-ms3/bin/elasticsearch-keystore add s3.client.default.access_key
/app/elasticsearch-ms3/bin/elasticsearch-keystore add s3.client.default.secret_key
kibana添加对象存储配置
# 重载默认密钥
POST _nodes/reload_secure_settings
# 7.5.1 正确的形式
PUT _snapshot/s3_repository
{
"type": "s3",
"settings": {
"bucket": "es-s3",
"endpoint": "test.minio.com:9000",
"path_style_access": true,
"protocol": "http",
"max_restore_bytes_per_sec": "50mb",
"max_snapshot_bytes_per_sec": "50mb"
}
}
# 不支持的形式
PUT _snapshot/my_s3_repository
{
"type": "s3",
"settings": {
"bucket": "es-s3",
"client": "test",
"access_key": "6AAB05L0AHCP1YT4UM0Z",
"secret_key": "WriVttuEUvHtx5V7gbQo+wpUeP3sJeiUUNq0ga4a",
"endpoint": "http://192.168.202.131:9000"
}
}
kibana查看存储库是否创建成功
GET /_snapshot/_all
GET _cat/repositories
GET _snapshot/s3_repository
如果需要删除
删除存储库
DELETE _snapshot/s3_repository
删除s3插件
./elasticsearch-plugin remove repository-s3
测试备份
# 备份了当前所有索引
PUT _snapshot/s3_repository/snapshot_test?wait_for_completion=true
GET _snapshot/s3_repository/_all
脚本备份
cat > /tmp/snapshot_tmp.json << EOF
{
"indices": "applogs-test-2024.05.21,applogs-test-2024.05.24",
"ignore_unavailable": true,
"include_global_state": false
}
EOF
curl -s -u elastic:123456 -X PUT -H "Content-type: application/json" -d @/tmp/snapshot_tmp.json "http://127.0.0.1:9200/_snapshot/s3_repository/snapshot_test3?wait_for_completion=true&pretty"
执行结果
[elasticsearch@test /]$ curl -s -u elastic:123456 -X PUT -H "Content-type: application/json" -d @/tmp/snapshot_tmp.json "http://127.0.0.1:9200/_snapshot/s3_repository/snapshot_test3?wait_for_completion=true&pretty"
{
"snapshot" : {
"snapshot" : "snapshot_test3",
"uuid" : "pbBLKw-ARra3DubsGtcfuw",
"version_id" : 7050199,
"version" : "7.5.1",
"indices" : [
"applogs-test-2024.05.21",
"applogs-test-2024.05.24"
],
"include_global_state" : false,
"state" : "SUCCESS",
"start_time" : "2024-07-23T06:43:19.558Z",
"start_time_in_millis" : 1721716999558,
"end_time" : "2024-07-23T06:43:19.961Z",
"end_time_in_millis" : 1721716999961,
"duration_in_millis" : 403,
"failures" : [ ],
"shards" : {
"total" : 3,
"failed" : 0,
"successful" : 3
}
}
}
Kibana
测试部署Kibana,版本和ES保持一致 7.5.1
资源下载
部署
root 用户准备目录
cd /app
tat -zxvf kibana-7.5.1-linux-x86_64.tar.gz
mv kibana-7.5.1-linux-x86_64 kibana
mkdir -p /app/logs/kibana
sudo chown -R elasticsearch:elasticsearch /app/logs/kibana
sudo chown -R elasticsearch:elasticsearch /app/kibana
su elasticsearch
切换 elasticsearch 用户后 进行配置编辑和启动
cd /app/kibana/config
cp kibana.yml kibana.yml.bk
vim kibana.yml
kibana.yml
# 推荐的调整的配置如下 并删除了多余注释
# 其他配置项和所有配置的具体含义参考 kibana.yml.bk 中的英文注释
server.port: 5601
server.host: "0.0.0.0"
server.basePath: "/kibana"
server.rewriteBasePath: true
server.maxPayloadBytes: 1048576
# 在生产环境中 这里推荐配置 ES 集群的协调节点
# 协调节点即 elasticsearch.yml node.master node.data 均设置为 false 的节点
elasticsearch.hosts: ["http://192.168.202.131:9200","http://192.168.202.131:9201","http://192.168.202.131:9202"]
elasticsearch.username: "kibana"
elasticsearch.password: "123456"
elasticsearch.logQueries: true
logging.dest: /app/logs/kibana/kibana.log
logging.verbose: true
i18n.locale: "zh-CN"
# 有时候 kibana 在查询对象存储库时会504超时 调整前端超时参数
elasticsearch.requestTimeout: 90000
编辑启动脚本
cd /app/kibana/bin
vim kibana
kibana 默认启动脚本最后添加node参数 –max-old-space-size=4096
如果不调整 kibana node 参数 可能在大数据量的查询下造成崩溃
NODE_OPTIONS="--no-warnings --max-http-header-size=65536 --max-old-space-size=4096 ${NODE_OPTIONS}" NODE_ENV=production exec "${NODE}" "${DIR}/src/cli" ${@}
增加启停脚本
vim start.sh
vim stop.sh
start.sh
nohup /app/kibana/bin/kibana 2>&1 &
stop.sh
pid=`ps -ef | grep kibana | grep node | awk '{print $2}'`
kill -15 $pid
启动kibana
sh start.sh
登录
访问:http://192.168.202.131:5601/kibana/login
用户:elastic
密码:xxxxx
账号密码在部署完成ES集群后需要自行重置,推荐设置成相同密码,参考ES章节的内容
角色管理
建议给logstash 创建单独用户和角色 logstash_writer
角色设置参考如下

通常在实际使用中,还会给其他使用者创建只读账号
如果想设置索引的只读用户,只读用户的角色集群权限无需赋予,只配置角色需关注的索引和增加索引权限 read, view_index_metadata, monitor 即可
Kibana高级设置
推荐对 Kibana 中的高级设置做出如下的调整
管理 > 高级设置
Date format
- 调整为 YYYY-MM-DD HH:mm:ss.SSS

Meta fields
- 调整为 _source, _index

Default columns
- 调整为 message

这些设置,主要是服务用户,让 Discover 更为优雅
- 进入 Discover 后默认展示 message 字段(实际日志内容)而不是 _source
- 使 Time 列 时间 更加可读
- 隐藏一些无需参加筛选的默认内置字段(例如 _type)
ES Stack监控
使用内部数监控(xpack.monitoring.collection.enabled: true)即可,可以不需要安装 Metricbeat,直接开kibana页面中启用
Stack 监控 >
点击使用内部数据监控,等待初始化几秒即可
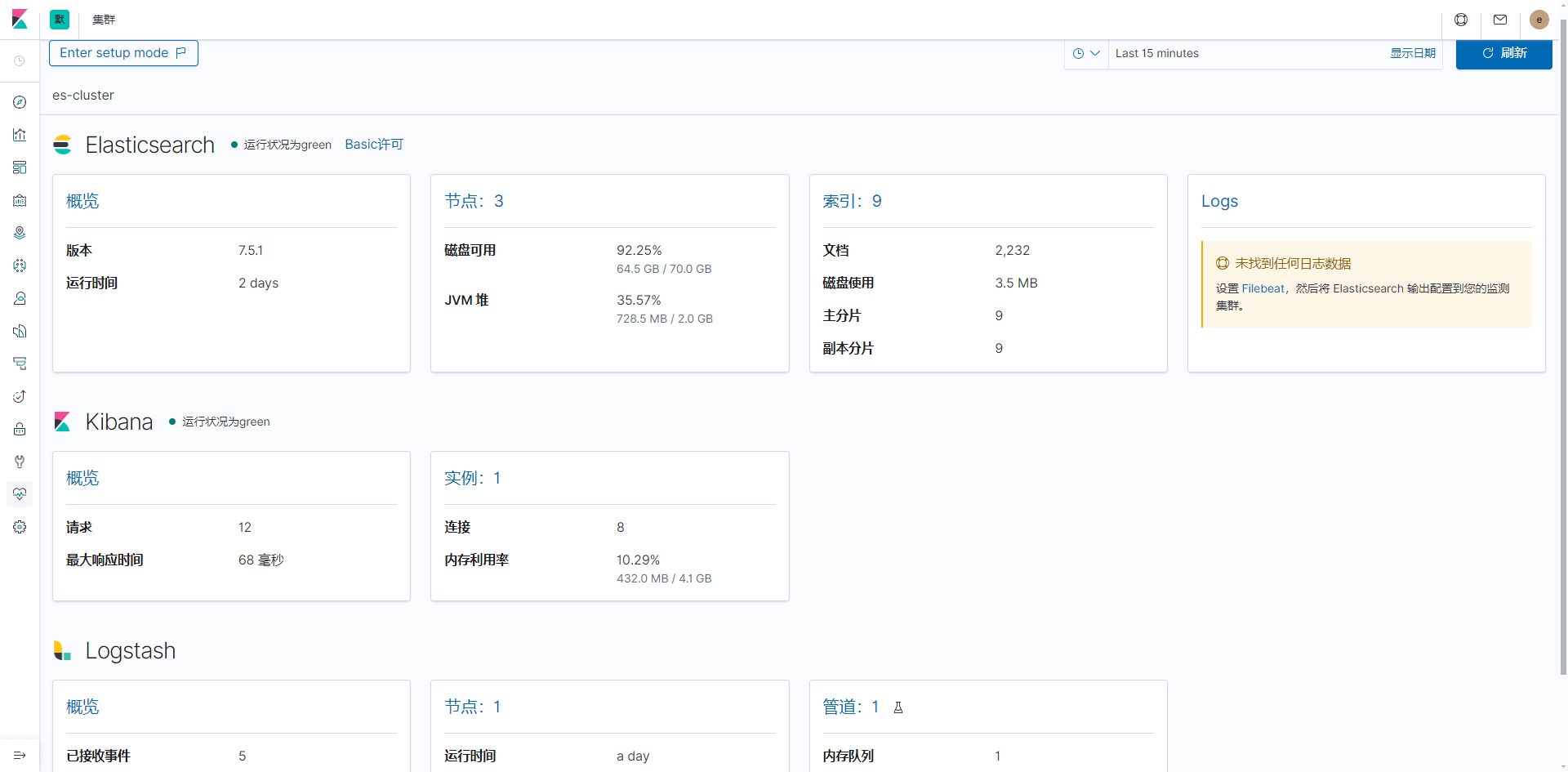
Stack 监控 > Elasticsearch 概览
可以查看 ES 集群的一些基础监控数据
常用 概览下的 分片活动 观察 ES 的分片迁移进度
Stack 监控 > Elasticsearch 概览 > 分片活动
(就不再粘贴图片展示了
管理索引
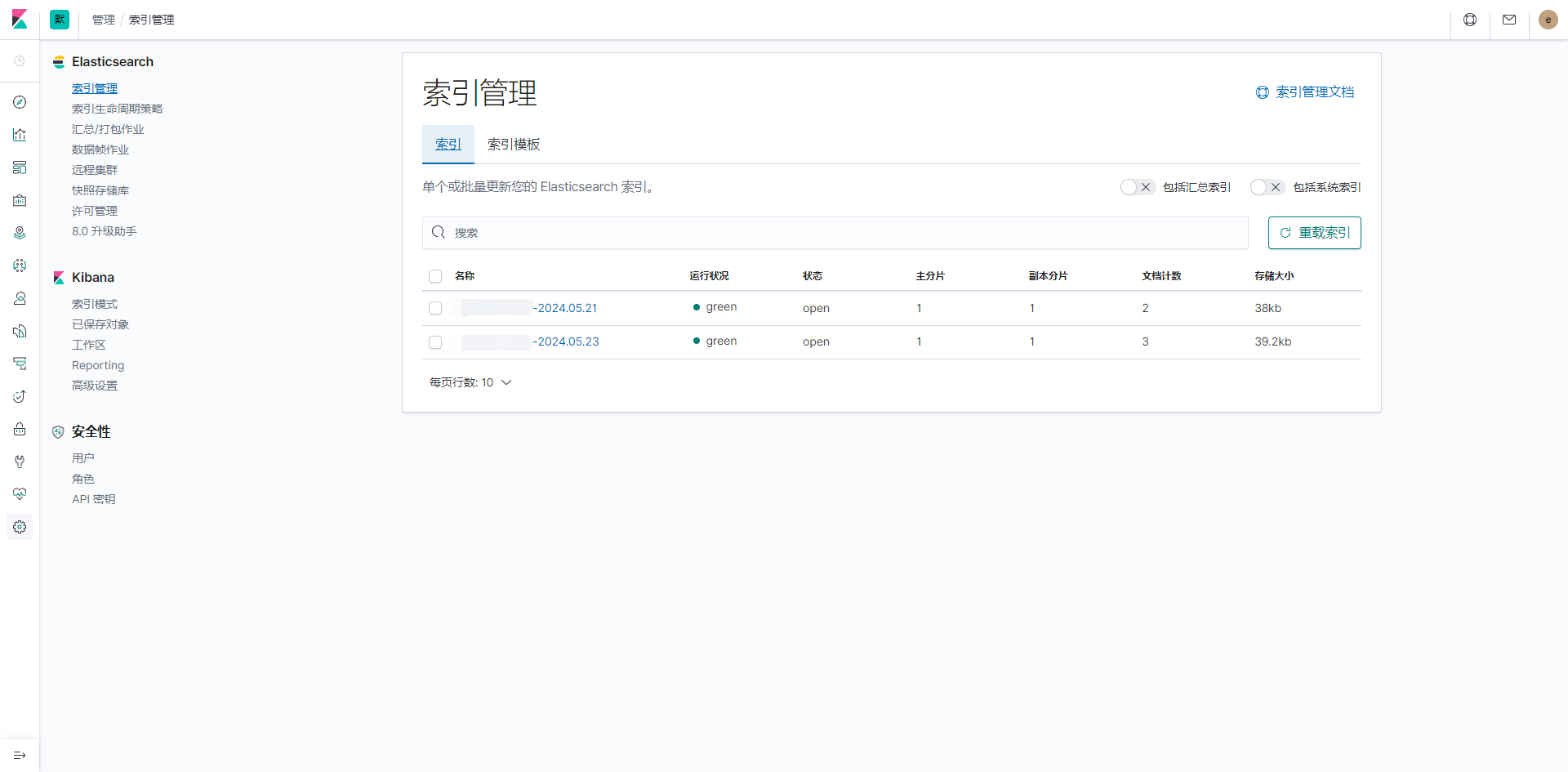
注意:如果完全按照本文档创建部署的 logstash 自动创建索引名称就是 applogs 开头
检查索引
首先需要检查是否成功创建日志索引
管理 > 索引管理 > 索引
索引模式
创建索引模式
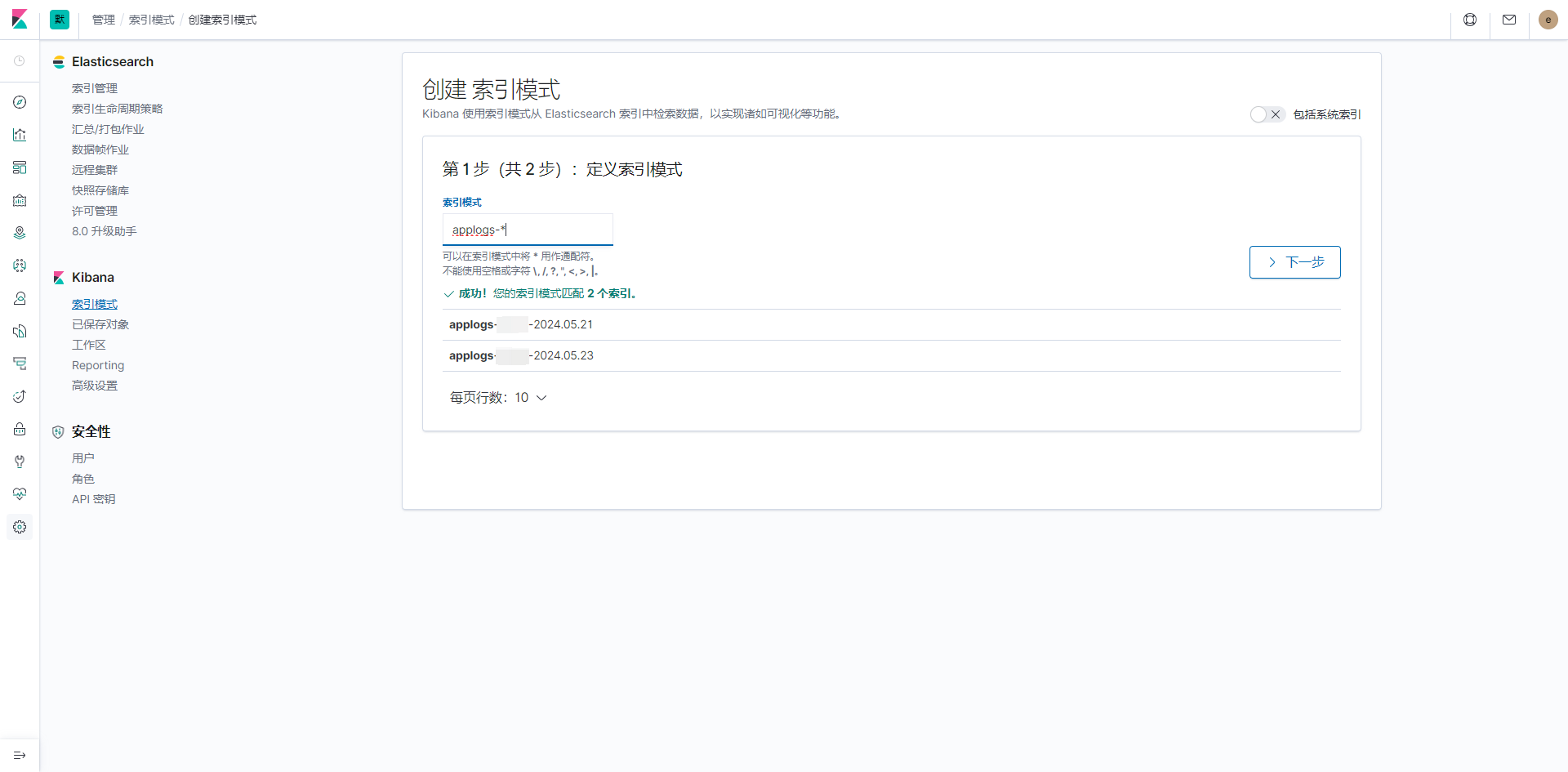
索引模板
索引模板主要是为了在创建索引时,如果没有设置相关分片、副本、映射等参数,则由相对应的模板内的参数决定
管理 > 索引管理 > 索引模板 > 操作 > 编辑
编辑模板
索引配置
比较重要的就是分片和副本数
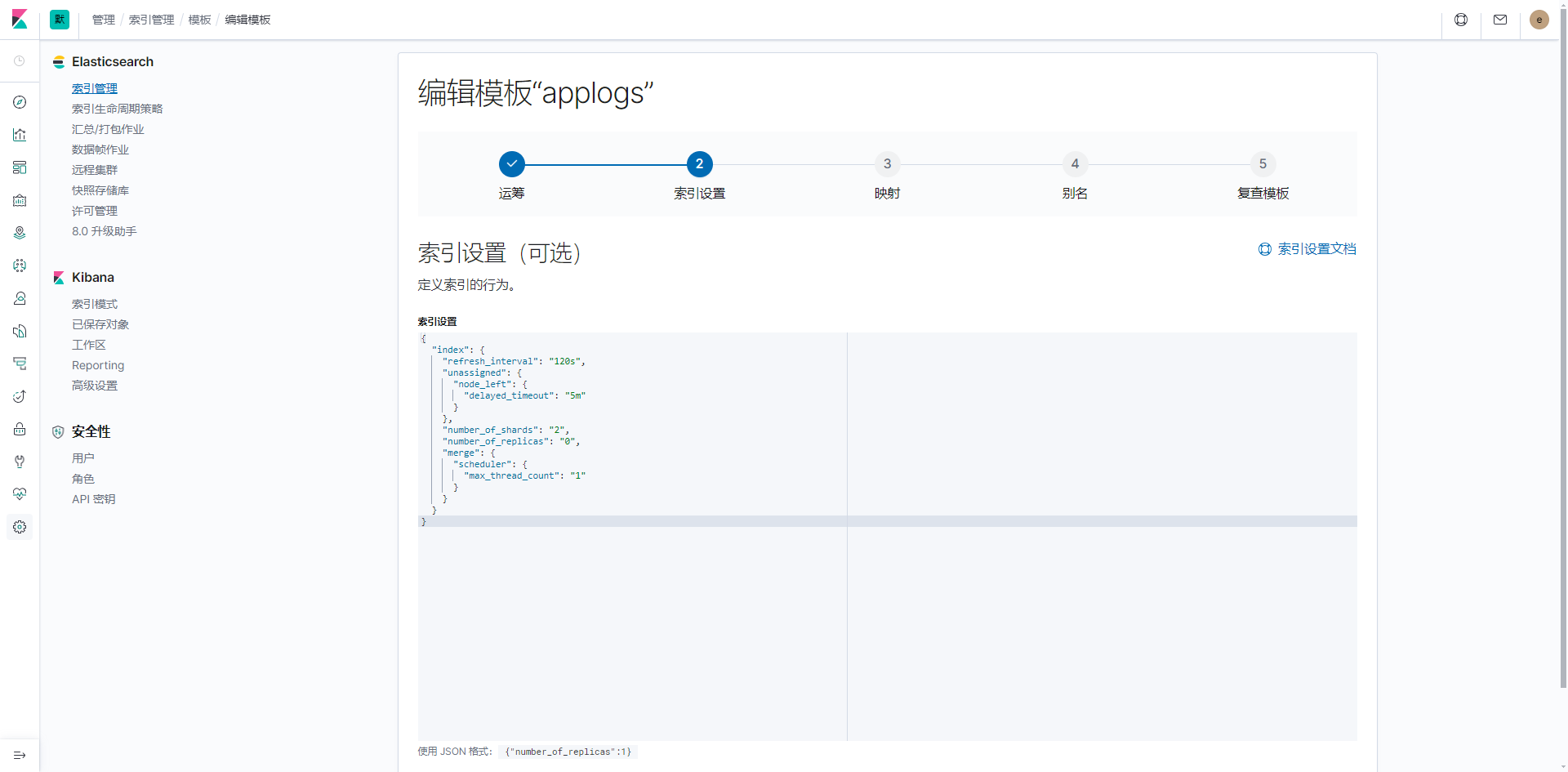
仅供参考
{
"index": {
"refresh_interval": "120s",
"unassigned": {
"node_left": {
"delayed_timeout": "5m"
}
},
"number_of_shards": "2",
"number_of_replicas": "0",
"merge": {
"scheduler": {
"max_thread_count": "1"
}
}
}
}
设置映射
logstash 默认创建的映射较为复杂
建议按需调整文档的字段类型
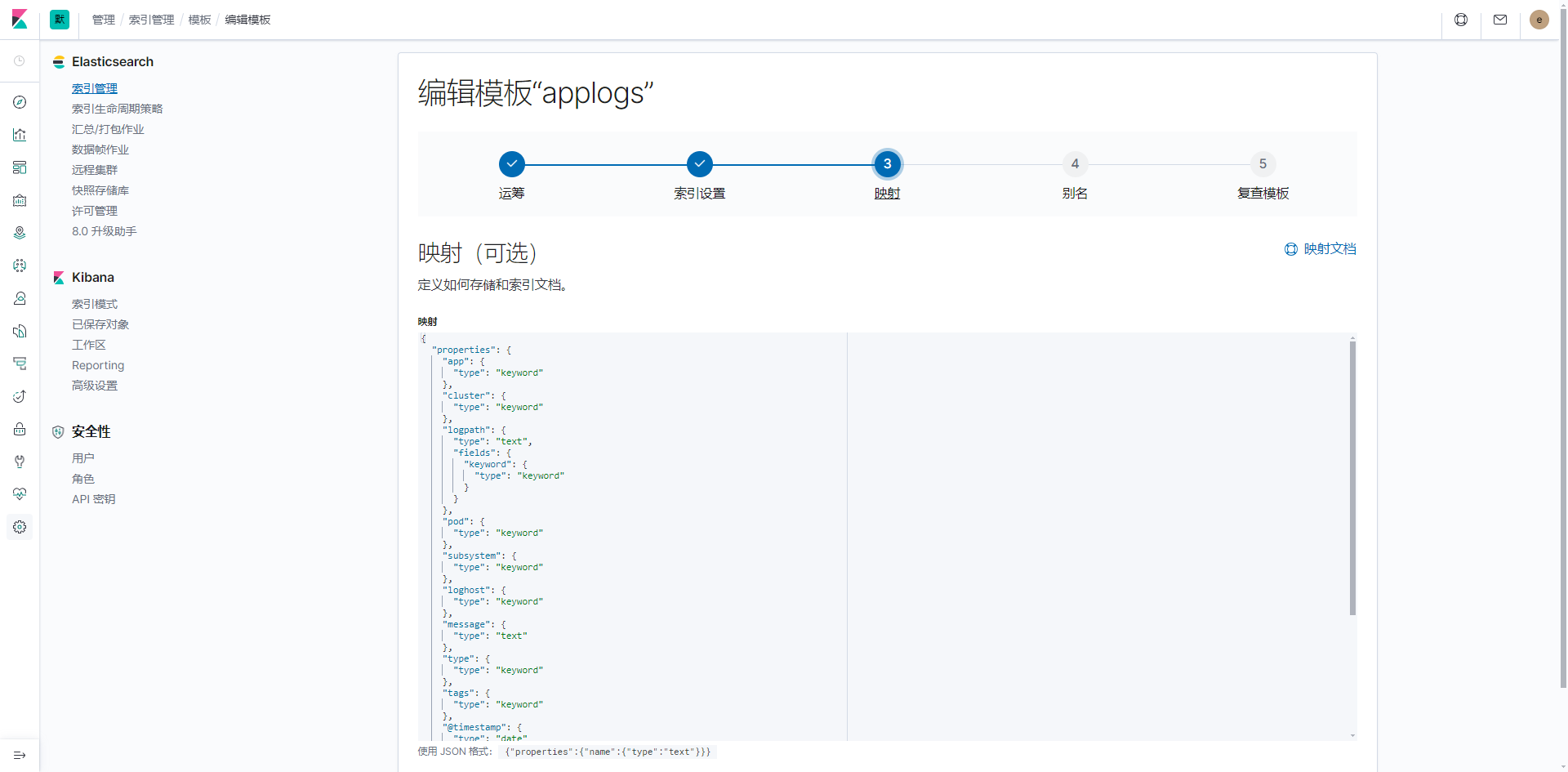
仅供参考
{
"properties": {
"app": {
"type": "keyword"
},
"cluster": {
"type": "keyword"
},
"logpath": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"pod": {
"type": "keyword"
},
"subsystem": {
"type": "keyword"
},
"loghost": {
"type": "keyword"
},
"message": {
"type": "text"
},
"type": {
"type": "keyword"
},
"tags": {
"type": "keyword"
},
"@timestamp": {
"type": "date"
},
"system": {
"type": "keyword"
},
"remote_ip": {
"type": "ip"
},
"loglevel": {
"type": "keyword"
},
"logtime": {
"type": "text"
}
}
}
常用集群管理场景
这里集群管理 主要指 使用 Kibana 开发工具的 Console 中, 对 ES 集群进行一些维护和管理工作
集群设置管理
# 查看设置
GET _cluster/settings
# 查看设置 包含默认值
GET _cluster/settings?include_defaults
# 如果不使用 kibana debug工具 使用 curl 建议增加 &pretty 参数使json包含换行符 返回结果可读
curl "http://127.0.0.1:9200/_cluster/settings?include_defaults&pretty"
# 查看集群健康状态
# 集群的健康状况为 yellow 则表示全部主分片都正常运行(集群可以正常服务所有请求),但是 副本 分片没有全部处在正常状态
GET _cluster/health
# 更新集群设置
# persistent 是永久策略 重启不失效
# transient 是临时策略 重启失效
# 优先级 Transient settings > Persistent settings > command-line settings > config file settings
# 建议 设置只设置 永久策略一种
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": "all",
"cluster.routing.rebalance.enable": "all"
},
"transient": {
"cluster.routing.allocation.enable": "all",
"cluster.routing.rebalance.enable": "all"
}
}
# 取消设置
# 对应配置改为 null 重新PUT
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": null,
"cluster.routing.rebalance.enable": null
},
"transient": {
"cluster.routing.allocation.enable": null,
"cluster.routing.rebalance.enable": null
}
}
集群分片设置
参考官方文档,主要涉及分片的分配和重新平衡,和一些分片参数
Cluster-level shard allocation and routing settings | Elasticsearch Guide [8.14] | Elastic
Size your shards | Elasticsearch Guide [7.17] | Elastic
# 设置分片的分配和重新平衡
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": "all",
"cluster.routing.rebalance.enable": "all"
}
}
# 查看当前集群有所分片数
GET _cluster/stats?filter_path=indices.shards.total
# 设置分片移动的并发数和节点分片限制
# 默认 7.x 节点最大分片数 1000
# 集群最大总分片数为 节点分片限制 * 活动数据节点数
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.node_concurrent_recoveries": "50",
"cluster.max_shards_per_node": "2000"
}
}
水位线调整
下面用搭建的模拟环境进行集群水位调整测试
# 设置水位线
# low: 低水位线 默认85% 磁盘使用达到85%时 禁止分配新的分片
# high: 高水位线 默认90% 磁盘使用达到90%时 会自动均衡分片到其他节点
# flood_stage: 泛洪线 默认95% 磁盘使用达到95%时 所有分片变成只读,禁止写入
# 注意
# 相关水位 达线后
# 副本分片无法写入会导致集群 YELLOW
# 主分片无法写入会导致集群 RAD
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.disk.watermark.low":"80%",
"cluster.routing.allocation.disk.watermark.high":"85%",
"cluster.routing.allocation.disk.watermark.flood_stage":"90%"
}
}
# 注意
# 最高水位线默认只能调整到95% 如果需要继续调高该值 则需要调整泛洪线后再调整高水位线和低水位线
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.disk.watermark.flood_stage":"98%"
}
}
索引管理
一些索引相关的设置
Index recovery | Elasticsearch Guide [7.5] | Elastic
Search settings | Elasticsearch Guide [7.17] | Elastic
# 设置索引恢复速度
PUT _cluster/settings
{
"persistent": {
"indices.recovery.max_bytes_per_sec":"80mb"
}
}
# 设置查询索引聚合分组时的最大桶数限制
# 可以通过查询默认设置 查看当前版本的值 7.5.1 默认 10000
PUT _cluster/settings
{
"persistent": {
"search.max_buckets" : "15000"
}
}
索引分片迁移
当分片大小分配的不合理时(例如几百G的索引分片数很少),会导致其中某台数据节点磁盘占用较高,此时就需要进行分片迁移手动调整大索引到空闲空间较多的数据节点中
还需要注意 如果你再执行备份索引的操作 不要迁移正在备份的索引
下面用搭建的模拟环境进行分片迁移测试
# 获取所有分片
GET _cat/shards
# 输出所有分片信息
# 分别展示了
# index: 分片所属的索引名
# shard: 分片的编号
# prirep: 分片的类型 p 表示主分片 r 表示副本分片
# state: 分片的当前状态
# docs: 分片中的文档数量
# store: 分片占用的存储空间大小
# ip: 分片所在的节点的IP地址
# node: 分片所在的节点名
# 省略部分 ...
applogs-test-2024.05.24 1 p STARTED 1 7kb 192.168.202.131 ms3
applogs-test-2024.05.24 0 p STARTED 0 230b 192.168.202.131 ms2
# 以 索引 applogs-test-2024.05.24 编号为 1 的分片 从 ms3 迁移到 ms2 为例
POST /_cluster/reroute
{
"commands" : [
{
"move" : {
"index" : "applogs-test-2024.05.24",
"shard" : "1",
"from_node" : "ms3",
"to_node" : "ms2"
}
}
]
}
# 输出
# 注意观察输出 迁移的索引分片状态均被调整为了 RELOCATING
# 成功迁移后 分片状态会恢复为 STARTED
{
"acknowledged" : true,
"state" : {
# 省略节点部分输出
# ...
"routing_table" : {
"indices" : {
"applogs-test-2024.05.24" : {
"shards" : {
"1" : [
{
"state" : "RELOCATING",
"primary" : true,
"node" : "RL77XAW3SSGF8F4L-NEnkw",
"relocating_node" : "DgSLzoz6QkWeoDBRKeilZQ",
"shard" : 1,
"index" : "applogs-test-2024.05.24",
"expected_shard_size_in_bytes" : 7312,
"allocation_id" : {
"id" : "LQ5EG039Q7S1dvPj1MeXUQ",
"relocation_id" : "kVPVi1wHQkqG6mjBKKYMRg"
}
}
],
"0" : [
{
"state" : "RELOCATING",
"primary" : true,
"node" : "DgSLzoz6QkWeoDBRKeilZQ",
"relocating_node" : "RL77XAW3SSGF8F4L-NEnkw",
"shard" : 0,
"index" : "applogs-test-2024.05.24",
"expected_shard_size_in_bytes" : 283,
"allocation_id" : {
"id" : "LqDERmEkSDiPc2SyEo0XZQ",
"relocation_id" : "aV9AT1scQIG7NuM9Gmr18g"
}
}
]
}
},
# 省略其他索引输出
}
},
"routing_nodes" : {
"unassigned" : [ ],
"nodes" : {
"DgSLzoz6QkWeoDBRKeilZQ" : [
{
"state" : "INITIALIZING",
"primary" : true,
"node" : "DgSLzoz6QkWeoDBRKeilZQ",
"relocating_node" : "RL77XAW3SSGF8F4L-NEnkw",
"shard" : 1,
"index" : "applogs-test-2024.05.24",
"expected_shard_size_in_bytes" : 7312,
"recovery_source" : {
"type" : "PEER"
},
"allocation_id" : {
"id" : "kVPVi1wHQkqG6mjBKKYMRg",
"relocation_id" : "LQ5EG039Q7S1dvPj1MeXUQ"
}
},
{
"state" : "RELOCATING",
"primary" : true,
"node" : "DgSLzoz6QkWeoDBRKeilZQ",
"relocating_node" : "RL77XAW3SSGF8F4L-NEnkw",
"shard" : 0,
"index" : "applogs-test-2024.05.24",
"expected_shard_size_in_bytes" : 283,
"allocation_id" : {
"id" : "LqDERmEkSDiPc2SyEo0XZQ",
"relocation_id" : "aV9AT1scQIG7NuM9Gmr18g"
}
},
## 省略其他输出
],
"RL77XAW3SSGF8F4L-NEnkw" : [
{
"state" : "RELOCATING",
"primary" : true,
"node" : "RL77XAW3SSGF8F4L-NEnkw",
"relocating_node" : "DgSLzoz6QkWeoDBRKeilZQ",
"shard" : 1,
"index" : "applogs-test-2024.05.24",
"expected_shard_size_in_bytes" : 7312,
"allocation_id" : {
"id" : "LQ5EG039Q7S1dvPj1MeXUQ",
"relocation_id" : "kVPVi1wHQkqG6mjBKKYMRg"
}
},
{
"state" : "INITIALIZING",
"primary" : true,
"node" : "RL77XAW3SSGF8F4L-NEnkw",
"relocating_node" : "DgSLzoz6QkWeoDBRKeilZQ",
"shard" : 0,
"index" : "applogs-test-2024.05.24",
"expected_shard_size_in_bytes" : 283,
"recovery_source" : {
"type" : "PEER"
},
"allocation_id" : {
"id" : "aV9AT1scQIG7NuM9Gmr18g",
"relocation_id" : "LqDERmEkSDiPc2SyEo0XZQ"
}
},
# 省略其他输出
]
}
},
"security_tokens" : { }
}
}
# 再次观察分片
GET _cat/shards
# 输出
# 可以观察到 主分片已经切换到 ms2
# 由于ES会自动平衡分片数 未被迁移的分片0会被自动从ms2迁移到ms3
# 可从 Stack Monitoring > Elasticsearch 概览 > 分片活动 > 已经完成恢复 验证分片活动 如下图
# 省略部分...
applogs-test-2024.05.24 1 p STARTED 1 7.1kb 192.168.202.131 ms2
applogs-test-2024.05.24 0 p STARTED 0 283b 192.168.202.131 ms3

滚动重启
官方文档对重启有较详细的说明:Full-cluster restart and rolling restart | Elasticsearch Guide 7.5] | Elastic
可以参考官方文档
下面是一些自己的实践总结
滚动重启前,建议停止所有的 logstash 和 kibana,然后对集群进行调整
集群滚动重启前需禁用分片自动分配,设置 cluster.routing.allocation.enable 为 none
否则节点停止后当前节点的分片会自动分配到其他节点上,本节点启动后需要等其他节点RECOVERING后才会RELOCATING,也就是分片在其他节点恢复后又会转移回来
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.enable":"none"
}
}
执行同步刷新,使内存数据落盘
POST _flush/synced
执行完毕后开即可开始重启ES节点 建议从 数据节点 -> 协调节点 -> 主节点的顺序重启
执行停止当前节点 ES
执行启动当前节点 ES
确认节点加入 ES 集群
GET _cat/nodes
确认重启节点加入集群后,再次开启分片自动迁移
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.enable":"all"
}
}
等待集群恢复
注意:需要当重启节点完全恢复正常,再进行下一个节点的重启操作
# 可以通过如下的 API 确认节点和索引信息
GET _cat/health
GET _cat/nodes
GET _cluster/health
GET _cat/recovery
重复上述的步骤
首先禁用分片迁移 > 执行同步刷新 > 重启ES > 打开分片迁移 > 等待集群Green
注意:在大数据量和ES集群规模较大时,滚动重启整个ES集群的过程会非常缓慢,日志收集的场景下可以缩短时间,停止ES集群上下游后,进行全部停止全部启动的操作