

💎
文章封面来自殘夜 ZANYA-🌟
最近生产上遇到一个比较复杂的网络问题,确实把天天摸鱼的我打的摸不着头脑,所以啊我这样的年轻人光会敲一些命令Ctrl C + V没卵用,遇到难题照样整不明白🤣
没办法现学现卖,实际看一看Docker的网络到底是如何实现的,才能有思路解决工作上遇到的疑难杂症🤔
如果你和我一样以前仅仅是会敲一些docker命令没有深入的去了解其中的原理,相信我,你耐心读完本篇文章会有所收获的
在阅读本篇文章之前,你可能需要有一些相关的知识储备:
- 了解熟悉iptables
- 有一定的网络基础
可能网络基础说的有些模棱两可,但是iptables的基础是读懂这篇文章的关键,目前我自己还没有对使用iptables做过一些总结,后面有时间卷会补上一篇iptables相关的文章,所以如果你没有接触过相关的知识推荐你可以先去阅读一下下面的博客:
这位运维大佬的总结的12章iptables相关知识读完之后真的是让人豁然开朗,下面一张关于iptables的流程图这是出自这位大佬的博客,这张图在本篇文章中会多次引用到它,这里我就先叫它为
iptables链路解析图
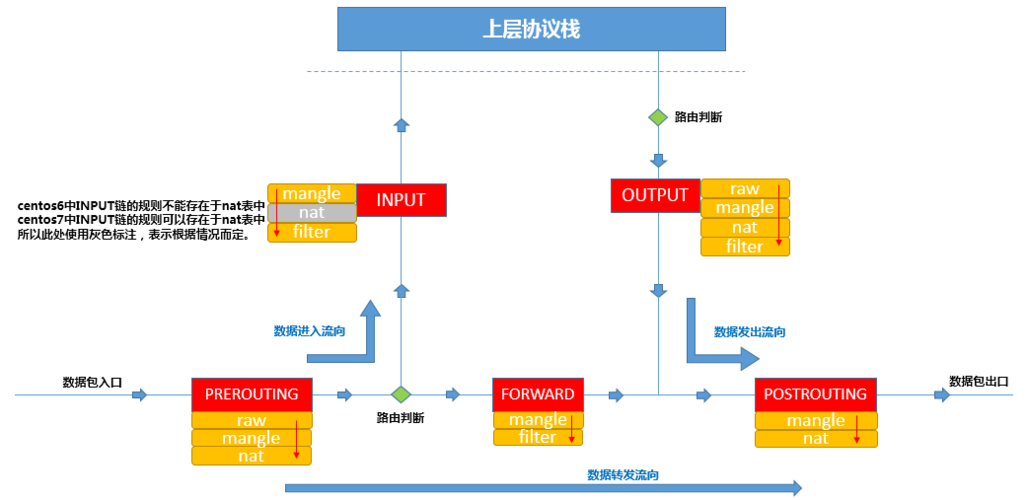
除了想感谢上面那位运维大佬前辈那么优秀的总结外,我的运维朋友HAHA 也给了我很多帮助,两人♂在深夜头脑风暴了很久才总算有了一些能说服自己的答案
准备工作
在了解原理之前,我们需要做一些准备工作,除了新建一个虚拟机(ip:192.168.70.6)做为实验环境外,我们还需要安装一些必要的东西,方便之后的讲解,下面是我在实际创建虚机时安装的相关东西
# 我是以最小安装 创建的centos7虚机 所以有些命令要先安装一下
yum install wget -y
yum install net-tools -y
yum install bridge-utils -y
# json格式化处理
wget -O jq https://github.com/stedolan/jq/releases/download/jq-1.6/jq-linux64
chmod +x ./jq
cp jq /usr/bin
创建完虚拟机之后,不用着急装docker,先观察一下空白虚拟机内部的网络环境,方便我们在安装docker之后弄懂,docker究竟对我们的宿主机动了什么手脚
-
检查最初的网卡
ifconfig
-
检查最初的路由
route -n
-
检查最初的raw表
# 注意 这里规则表的检查 只先只关注 系统五大默认链即可 # 分别是 PREROUTING INPUT FORWARD OUTPUT POSTROUTING # 当前raw表 包括下面的其他三张表的检查 都是只展示了属于默认链的相关规则 iptables --line-numbers -t raw -nvL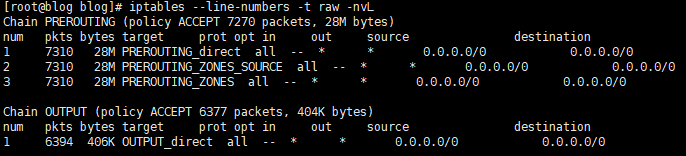
-
检查最初的mangle表
iptables --line-numbers -t mangle -nvL
-
检查最初的nat表
iptables --line-numbers -t nat -nvL
-
检查最初的filter表
iptables --line-numbers -t filter -nvL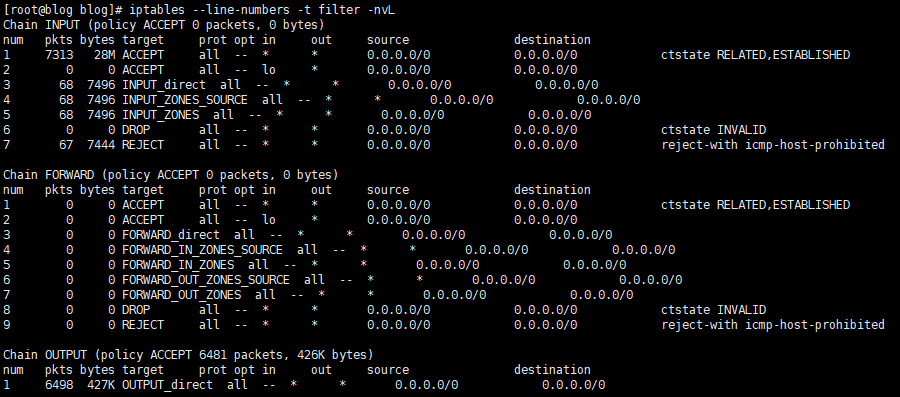
下面我们快速装一下Docker
# 获取最新docker版本二进制包
wget https://download.docker.com/linux/static/stable/x86_64/docker-20.10.9.tgz
# 解压
tar zxvf docker-20.10.9.tgz
# 安装
cp ./docker/* /usr/bin/
# 赋权
chmod +x /usr/bin/docker*
chmod +x /usr/bin/containerd*
chmod +x /usr/bin/runc
chmod +x /usr/bin/ctr
# 创建根本目录
mkdir -p /docker-root
mkdir -p /etc/docker
# 创建配置文件
vi /etc/docker/daemon.json
# daemon.json 配置如下
{
"data-root":"/docker-root"
}
# 启动
# docker.service内容太多了就不贴了 我的DOCKER从入门到入土上半章节有相关详细的安装 里面有贴相关内容
cp ./docker.service /usr/lib/systemd/system/
systemctl daemon-reload
systemctl enable docker
systemctl start docker
Docker安装后
安装完Docker以后,别着急启动容器,我们再检查一些相关的网络配置,看看Docker为我们宿主机带来了哪些变化
-
检查安装Docker后的网卡
# 可以发现多出了一张docker0的网卡 ifconfig # 可以通过brctl查看到 当前docker0属于一个网桥 brctl show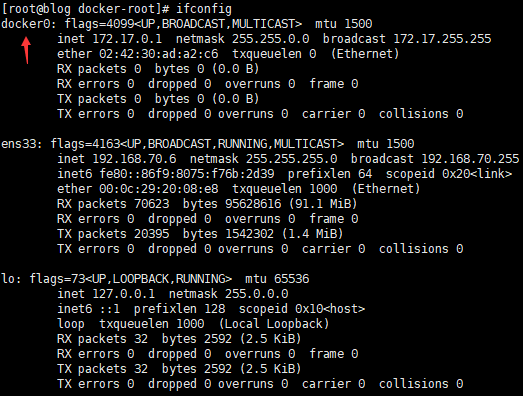

-
检查安装Docker后的路由
# 自动增加了docker0的路由 route -n
-
检查安装Docker后的raw表
# 安装docker后和安装前对比raw其实是没有变化的,这里就不贴图了 -
检查安装Docker后的mangle表
# 安装docker后和安装前对比mangle也没有变化的,这里同样就不贴图了 -
检查安装Docker后的nat表
# 对比可以发现 # 在nat表中 # docker在PREROUTING的链中增加了名为DOCKER的自定义链 # docker在OUTPUT的链中增加了名为DOCKER的自定义链 # 没有任何容器时 DOCKER链没有太大意义 RETURN动作表示返回 # 结合我们的 iptables链路解析图 # nat在PREROUTING的最下方 RUNTURN之后就会直接根据是否属于当前网卡ip 判断下面的链路如何进行 # 这里规则只有 RUNTURN 其实就是未做任何调整 跳过了PREROUTING链 iptables --line-numbers -t nat -nvL iptables --line-numbers -t nat -nvL DOCKER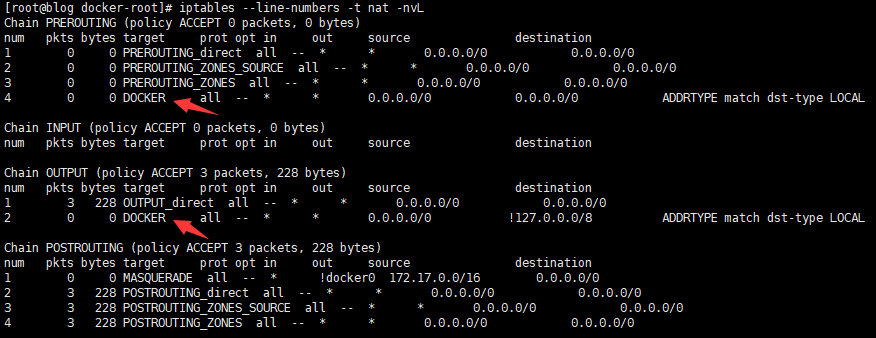

-
检查安装Docker后的filter表
# 通过对比我们可以看到filter表在FORWARD链中改动还是比较大的 # FORWARD中关联了三个docker自定义链 # 分别是DOCKER DOCKER-USER DOCKER-ISOLATION-STAGE-1 iptables --line-numbers -t filter -nvL # 继续往下查看这些自定义链路可以得知 # 在未启动容器前 DOCKER DOCKER-USER 链其实也都是没有意义的 一个是空 一个是 RETURN # DOCKER-ISOLATION-STAGE-1 稍微有些不同 # 其中链路的规则表示 从docker0网卡出去 到其他除了自身网段以外的所有地址 进入DOCKER-ISOLATION-STAGE-2链 iptables --line-numbers -t filter -nvL DOCKER iptables --line-numbers -t filter -nvL DOCKER-USER iptables --line-numbers -t filter -nvL DOCKER-ISOLATION-STAGE-1 # 继续查看DOCKER-ISOLATION-STAGE-2链 # 在没启动容器之前 DOCKER-ISOLATION-STAGE-2链 其实也是没有意义的 # 我们通过匹配了 目标网卡是docker0以外的流量进入DOCKER-ISOLATION-STAGE-2链 # 其中第一条规则 匹配目标网卡是docker0 恰恰和进入的条件相反 所以不匹配 进入了规则2 # 同样规则2 任意出入地址全部RETURN又跳出了当前的链路 # 等于进来逛了一圈 啥也没干又走了 iptables --line-numbers -t filter -nvL DOCKER-ISOLATION-STAGE-2

一顿分析后,简单总结一下
- Docker安装后为我们默认创建了docker0虚拟桥接网卡
- Docker安装后为我们默认填了桥接网卡的路由地址
- Docker安装后就操作了两张表,分别是nat和filter,从nat表得知docker在PREROUTING链中引入自定义链,从filter表得知docker在FORWARD链引入了自定义链,后面重点照顾这两张表上的规则即可
启动容器测试
“没启动容器前,上面的这么些总结不都是很简单吗?菜鸟都知道,你也好意思拿来水文章?”
别着急我们继续启动容器做测试😐
-
busybox跑起来
# 拉一下 docker pull busybox # 随便执行个命令把busybox挂住 随便映射一个没意义的端口 # 这时候看看docker又为我们做了些啥 docker run --name box -p 8081:80 -d busybox sleep 100000
-
启动容器后检查网卡
# 可以发现多了 一个编号是7的网卡接口 ip a # 通过brctl可以发现 确实是多了一个插口 brctl show
-
启动容器后检查容器内部网络
# 进入容器 docker exec -it box sh # 查看容器路由表 没啥特殊的 网关地址docker0 路由到docker0了 route -n # 容器里面也有一张 编号是6的网卡 # 仔细观察一下 # 宿主机编号是7的插口名称是 vethXXX@if6 # 容器内网卡编号是6网卡名称是 eth0@if7 # 就算不懂都从名称上都能看出来 这两个东西是成对的了吧 毕竟名字都@了对方 # 其实这是 veth pair 是一对相互连接网络接口 ip a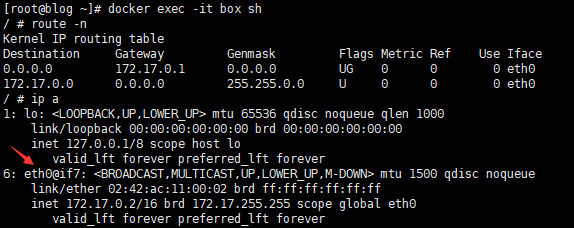
关于 这里的内容可以参考一下我的另外一篇文章里的解释
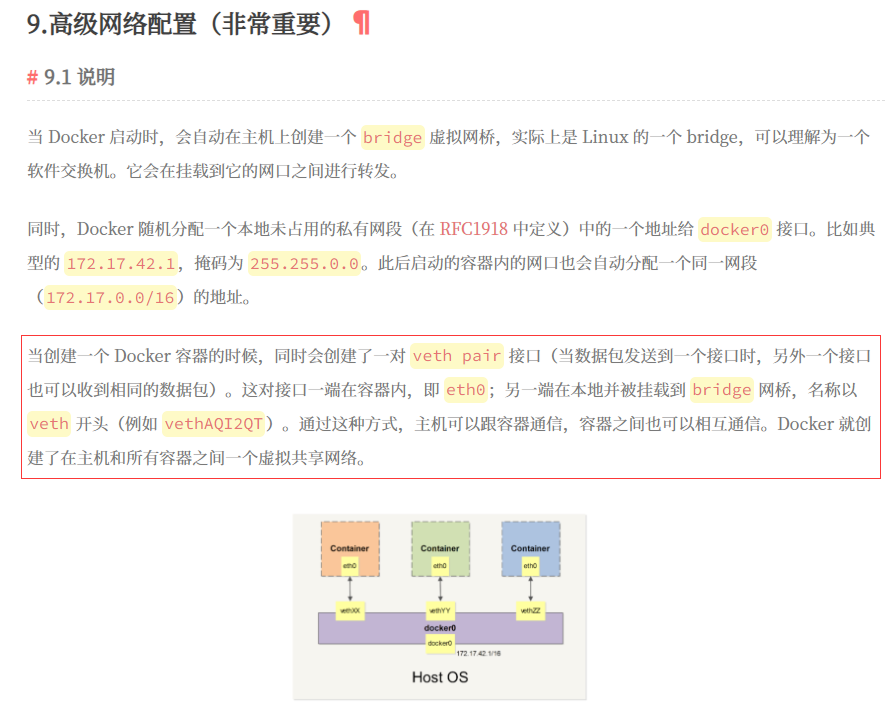
如果还是不理解,可以看看关于 veth pair 更详细的资料-来自逼乎
-
启动容器后检查进程和监听
搞定容器是通过veth pair创建接口与当前虚拟网桥相连来保证网络连接后
通过常识,我们知道我用docker启动了一个容器还开启了端口映射,端口监听一定是起来的,我们来详细看一下
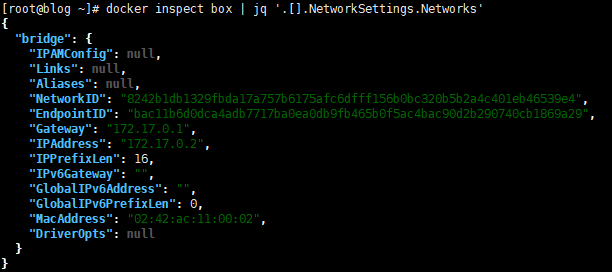
# 先查看进程 # dockerd 起来了两个子进程 都是docker-proxy # 仔细观察 两个进程的参数 分别是ipv4格式和ipv6格式的宿主机ip 宿主机端口 和 容器的ip和容器端口 # 看起来就像是在搞代理啊 ps -ef | grep docker # 查看监听 确认一下 确实是docker-proxy在监听 netstat -ltnp | grep -E 'docker-proxy' # 确认一下容器ip 172.17.0.2 确实是我启动的busybox ip docker inspect box | jq '.[].NetworkSettings.Networks'
乍一看,“这不是很简单,起了监听给外面用的啊,通过docker proxy监听宿主机端口然后转到容器了呗”
但是真是这么简单的吗?接着检查,还有最后一个iptables的规则没有看
-
启动容器后检查nat和filter表
在未启动容器前,我们通过对比就发现了,docker只操作了nat和filter表,这里我们也直接重点看这两个表的变化
# 查看net表 这里居然多了一条规则 docker为我们生成了一个DNET规则 # 这个条规则的意思是 如果来源的网卡不是docker0 且访问的端口是 8081 则全部DNET成 容器ip:80 # 这就有点意思了 能感觉和docker-proxy的功能冲突了呢 一个监听宿主机端口做转发,一个在iptables做DNET到容器 这咋回事 iptables --line-numbers -t nat -nvL DOCKER # 继续看filter表 # filter表同样也多加了一条规则 # 这条规则 表示从docker0网段以外的地址进入docker0端口是80的全部放行 # 加上我们先前的总结 这是属于FORWARD链上规则 iptables --line-numbers -t filter -nvL DOCKER iptables --line-numbers -t filter -nvL DOCKER-USER iptables --line-numbers -t filter -nvL DOCKER-ISOLATION-STAGE-1 iptables --line-numbers -t filter -nvL DOCKER-ISOLATION-STAGE-2

通过检查启动容器之后,docker为我们带来变化,很自然能发现有一个问题
到底我们从外部进入容器是通过docker-proxy还是iptables的DNET啊?
这时候,我们就需要结合iptables链路解析图做一些头脑风暴了,通过链路可以知道,其实流量进入我应用这个过程,iptables的链路过滤总是在前面的,
至少请求的包会通过,PREROUTING和INPUT两个链路,最终发送到用户空间,而只有在经过linux内核发送到用户空间之后,请求才会真正的被我们的应用所捕获(简单来说就是只有通过了INPUT链,发送到用户空间之后,我们的端口监听才会真正的生效啊),所以就可以大胆的猜想了,对应我测试虚拟机的例子,我访问宿主机ip:8081的时候,首先第一步就是经过了PREROUTING,就直接被DNET掉了,路由到了我的docker0网段中,然后进入的容器,docker-proxy在这一步是没有啥作用的
总之,猜测的结论就是从docker0外部进入的包,全部是通过DNET转发,这时docker-proxy并不在我们的请求链路中(docker-proxy在摸鱼)
由于这里我启动的是一个假的应用,我的busybox实际上没有东西跑在容器的80端口上,这里我换一个nginx来验证一下我的猜想
证明docker-proxy在摸鱼
首先强调一下,我们验证的情况是入网的情况,也就是从外部访问到容器内部的情况,也是我们最常用的,跑个容器供外部访问
这里我准备了一个Nginx容器,里面访问默认的html进行了一些简单的修改,表示Nginx里面有我们实际的需要访问网站
验证的思路就是,如果在访问这个Nginx下的网站时,检测到PREROUTING链和FORWARD链上有对应的流量发生,且网页能正常访问
即证明,我们猜测的链路是正确的
-
启动
docker run --name ng1 -d -p 8001:80 lkarrie/nginx1
-
检查访问前nat表PREROUTING链流量
# 记住红框框起来的数字 这很重要 # 如果你了解 iptables 肯定知道框出来的内容 其实也很简单 # pkts表示匹配当前规则的包 byts表示大小 # 通过这些数字变化判断是否经过当前的链路 iptables --line-numbers -t nat -nvL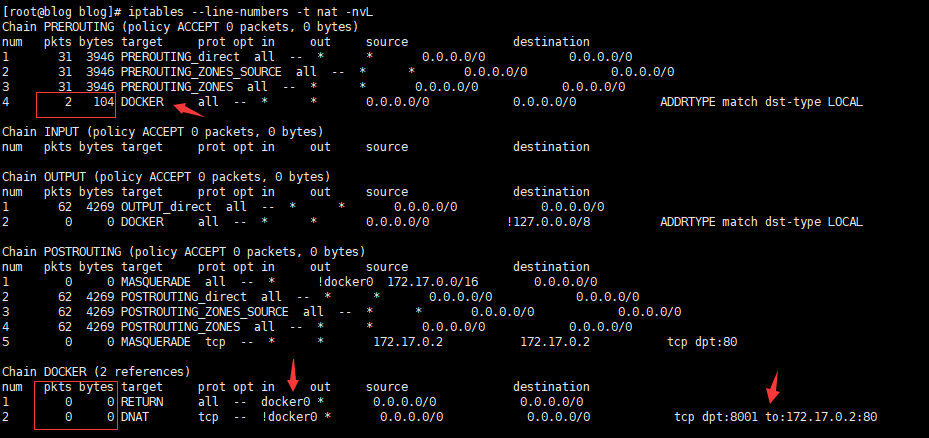
-
检查访问前filter表FORWARD链流量
# 记住红框框起来的数字 这很重要 iptables --line-numbers -t filter -nvL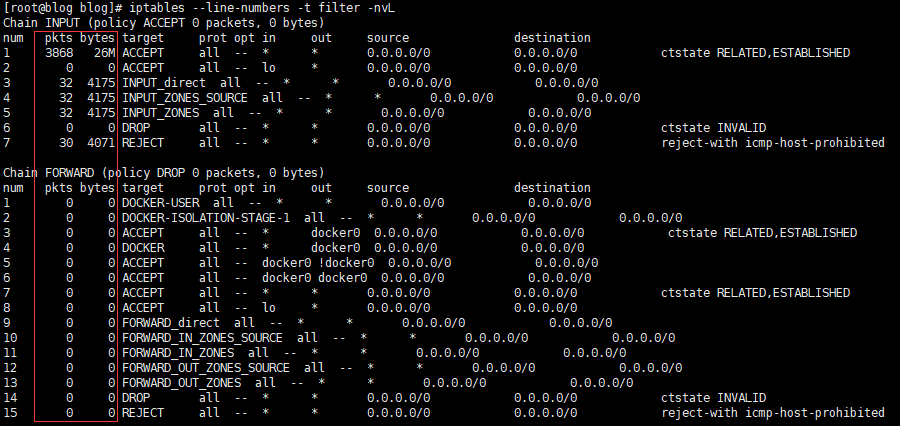
-
访问http://192.168.70.6:8001
# 可以看到 网页正常返回了
-
检查访问后nat表PREROUTING链流量
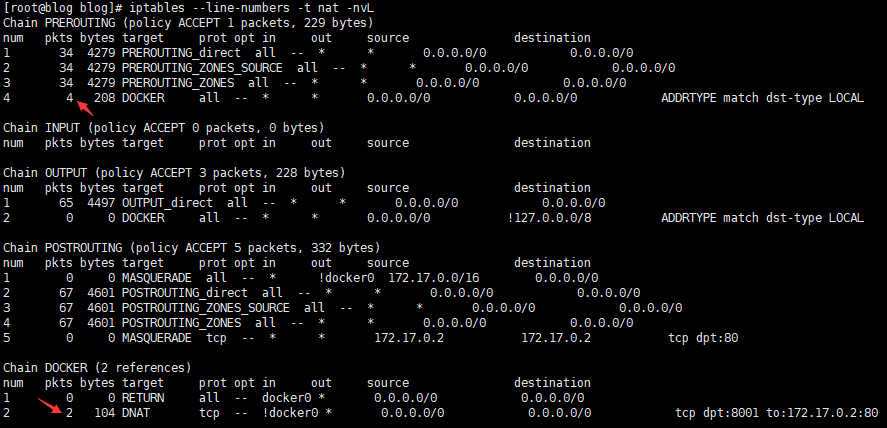
-
检查访问后filter表FORWARD链流量

可以很明显的发现,匹配的包数据变化了,证明我们的想法没有错
但是光是这样,有人可能就要说了,你这仅仅是证明它从PREROUTING链到了FORWARD链啊,你怎么知道docker-proxy就没参加工作,它在摸鱼
而且细心的人可能发现了,filter表中input链的数字也增加了,通过input链不就进入了用户空间了吗?进入进程了吗?
关于filter表中INPUT链的包数据为什么增加了,我稍后会解释一下
为了证明docker-proxy确实在摸鱼,我们把docker-proxy直接杀掉🥲,再访问我们的网页,如果这时包数据发生了变化,而且网页能正常访问,应该就能完完全全证明,docker-proxy在摸鱼了吧,包进来要它没它都能用
-
直接杀掉docker-proxy,断掉宿主机监听
# 可以看到下图中的 我执行的命令 # kill掉 docker-proxy之后 # 宿主机监听消失了 # docker ps 看了一下 容器还是在正常运行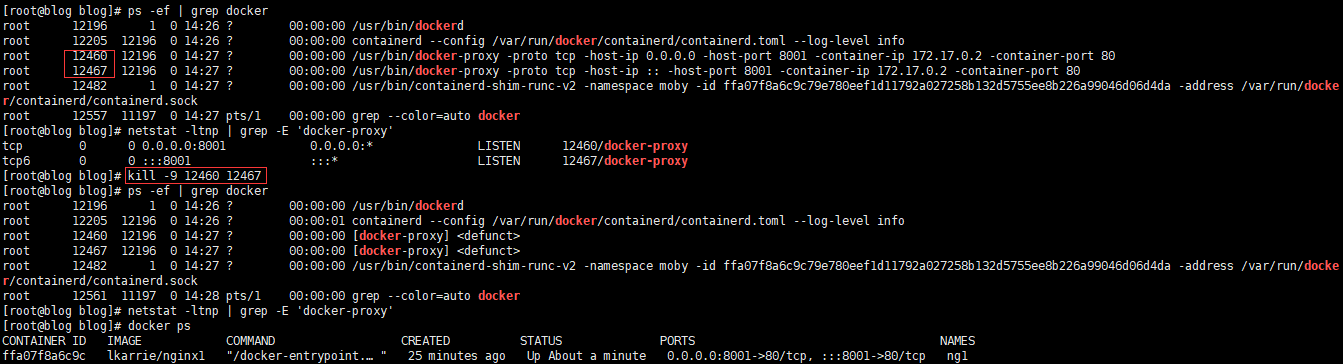
-
再次访问 http://192.168.70.6:8001
# 为了防止浏览器缓存 我换一个火狐去访问 # 嘿 同样也没问题哦 # 宿主机端口监听都挂了 docker容器还是能正常对外提供服务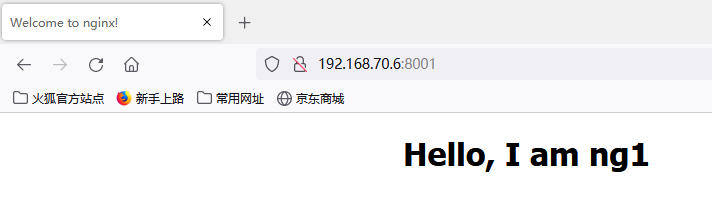
-
检查kill进程后nat表PREROUTING链流量
# PREROUTING的bytes变大了 # (关于PREROUTING 显示DOCKER链 数量为什么没有增加我也没想清楚 但是这无伤大雅下面DNET的包变化完全就能证明经过了DNET) # 同样DOCKER链的DENT规则也有相应的包增加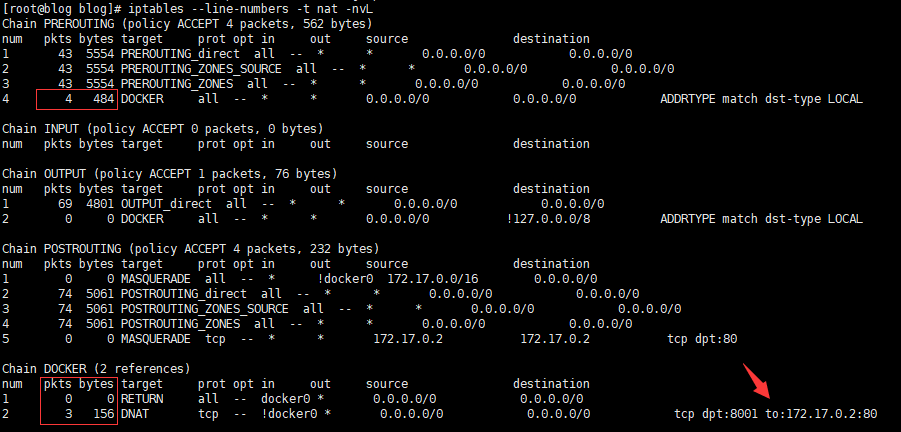
-
检查kill进程后filter表FORWARD链流量
# 同样FORWARD包存在变化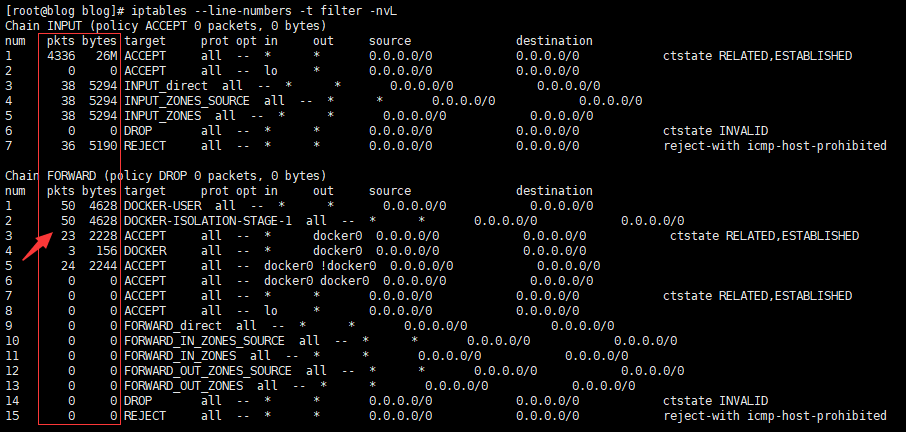
这样足够能够证明这种情况下,docker-proxy在摸鱼了吧
最后解释一下关于filter表中INPUT链的数据包的增加
个人理解,当请求被DNET之后,其实还有一个从docker0网卡到容器的一个过程,这个过程相当于172.17.0.1到172.17.0.2,他其实也是经过iptables的,网卡内部的流量当然不会再FORWARD出去,直接进入了INPUT链到容器了
如果上面这一段你不理解,或者觉得我的想法有问题,你可以当我在这理发店🤭
其实我觉得都把端口监听干掉了(也是就是杀掉了docker-proxy)我的Nginx还能正常访问就足够可以证明docker-proxy在摸鱼了
外部流量进入docker0网段的情况下,全是iptables的DNET在辛苦工作
如果你读到这里了,你可能会思考,这个docker-proxy到底是干嘛的,这不是明摆着没用么
存在即合理,它当然有它自己的用处,下面的章节,我就不再这样抛砖引玉的去说明问题了,加快节奏用一个实际的例子来说一说docker-proxy在什么情况下会起到作用
证明docker-proxy的价值
刚刚证明了从外部进入容器内的链路docker-proxy在摸鱼,那么从容器内部访问外部网络又是怎样的呢,其实从容器内部访问外部网络,这时docker-proxy就成了一个非常重要的“螺丝钉”了,下面来实际看看docker-proxy在这种情况发挥了什么作用
-
首先恢复监听
# 重启容器即可恢复kill掉的监听 docker restart ng1 ps -ef | grep docker # 可以看到8001端口监听重新恢复了 netstat -ltnp | grep -E grep 'docker-proxy' docker ps

-
进入容器访问宿主机8001(nginx的宿主机端口映射)
docker exec -it ng1 sh # curl之后可以看到有正常的html内容返回 curl -i http://192.168.70.6:8001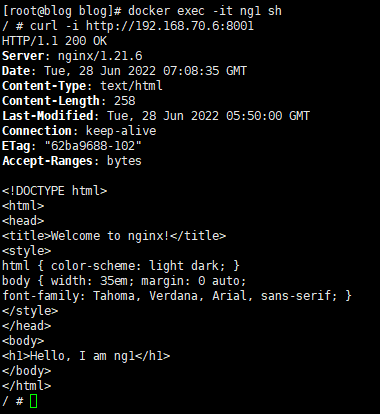
-
从容器到访问宿主机8001(nginx的宿主机端口映射)链路分析
首先结合下面的nat表,分析一下iptables
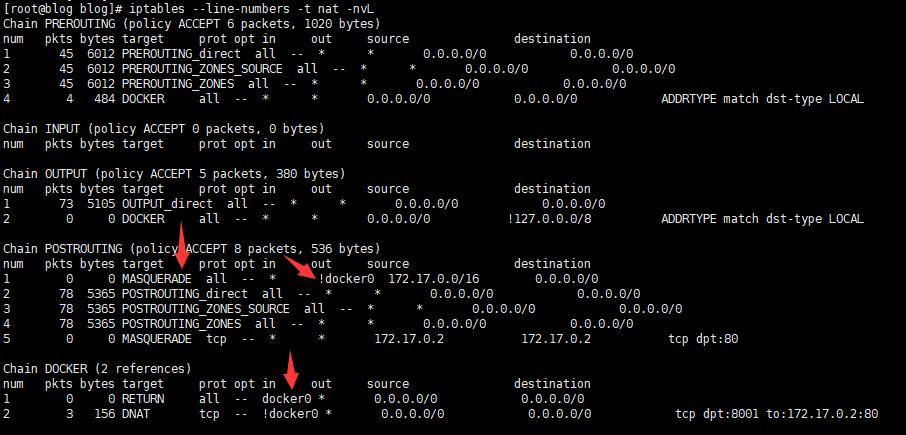
容器内部访问宿主机IP(从容器ip到路由到docker0网卡,再从docker0网卡跳到ens33,最后进入宿主机的用户空间)的过程
首先docker0 跳 ens33
同样会通过PREROTING链到DOCKER链,但是DOCKER链中并不会经过DNET,可以看到DOCKER链中的规则1,所有从docker0网卡来的流量全部RETURN,这条规则匹配从容器内部往外部访问,则不会再经过DNET
除了不会经过DNET,我们可以看到在iptables的最后一步POSTROUTING链中,存在一条SNET规则(图中POSTROUTING链中的规则1),将所有目标网卡不是docker0的请求且网段属于docker0的网段,全部执行MASQUEADE动作,也就是覆盖请求来源ip为docker0的网卡的ip(将来源修改为docker0网卡ip也是为了请求返回时可以找到docker网卡从而返回容器)
ens33 将请求发往宿主机用户空间
此时请求还会经过一遍iptables,同样来源为docker0网卡(此时请求来源ip已经被SNET成docker0网卡ip也就是172.16.0.1)不会进行DNET,同时请求目标ip为宿主机ip,不会再进入FORWARD链,而是进入INPUT链
请求成功响应
分析到这里其实我们已经不用在分析INPUT链中到底链路是什么样了,最终请求都会进入到宿主机用户空间,从而被进程的端口监听捕获最终转发到容器获取到返回的html报文,所以到这一步我们推测其实最终是docker-proxy生效将请求又转发到容器获取到了返回报文
-
验证docker-proxy起了请求转发的作用
如果刚刚的链路分析你没有看懂,没关系我们可以直接通过测试结果去验证,首先将docker-proxy进程kill掉之后,再从容器重复刚刚成功的curl请求,如果访问不通,即证明docker-proxy在这个过程起了关键的作用
# kill docker proxy ps -ef | grep docker kill -9 12702 12710 netstat -ltnp | grep -E grep 'docker-proxy' # curl # curl之后可以看到我们的请求被拒绝了 Connection refused docker exec -it ng1 sh curl -i http://192.168.70.6:8001
通过以上的步骤测试,我们的测试结果证明了,docker-proxy在某些情况中也有着自己的作用,它并不是完全在摸鱼
IPTABLES还为docker做了什么
上面两小章节,我们分别通过两种情况,发现了iptables和docker-proxy都有各自的一些作用
这里再补充一个iptables比较重要的作用
如果你有使用docker的经验或是学习过docker,应该都知道我们可以创建新的桥接docker network,而且这些分别创建的网络都是互相隔离,这里的网络隔离也是通过iptables实现的
下面我们实际来验证一下
-
创建一个新的桥接网络
# 创建新的网桥 bridge1 docker network ls docker inspect 6d8 | jq '.[].IPAM' # 创建名为bridge1 网卡名为docker1的网络 # 可以从下面的图中看到 新建的网卡 名字确实也是docker1(编号19的网卡) docker network create bridge1 -d bridge -o com.docker.network.bridge.name=docker1 --subnet "172.18.0.0/16" --gateway "172.18.0.1" # 创建网桥之后,再新的网桥中运行了另外一个nginx 容器名为ng2 docker run --name ng2 -d -p 8002:80 --network bridge1 lkarrie/nginx2

-
从ng2访问ng1验证网络隔离
# 查看ng1 ip docker inspect ng1 | jq '.[].NetworkSettings.Networks' # 进入ng2 访问ng1 docker exec -it ng2 sh curl -i http://172.17.0.2:80 # 从图中可以看到curl超时了 推出容器 exit # 退出后 从外部访问ng1 没有问题 curl -i http://172.17.0.2:80
-
从ng2访问ng1 iptables链路分析
# 这里就不再从PREROUTING链开始分析了 # 从ng2到ng1 实际上是 docker1到docker0 # 一定是会走FORWARD链路的 # 运行命令结合下面的图我们可以看到FORWARD链路中docker填加的规则 iptables --line-numbers -t filter -nvL FORWARD iptables --line-numbers -t filter -nvL DOCKER-ISOLATION-STAGE-1 iptables --line-numbers -t filter -nvL DOCKER-ISOLATION-STAGE-2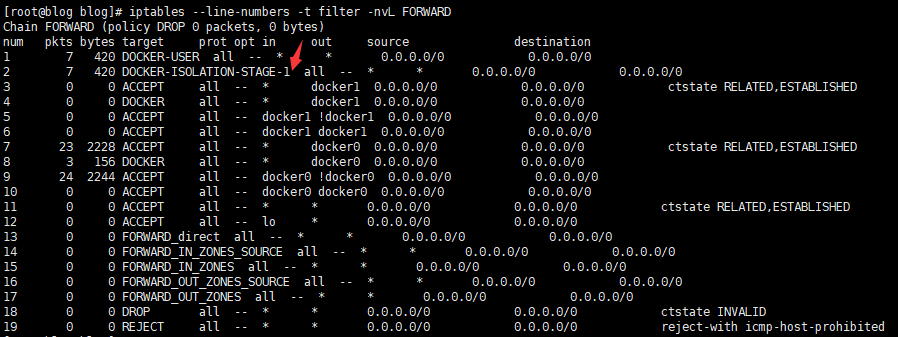


分析:在FORWARD链中首先是经过了DOCKER-USER链然后进入DOCKER-ISOLATION-STAGE-1链,DOCKER-USER这里是空链,图中没展示也不再赘述了,通过查看DOCKER-ISOLATION-STAGE-1链,我们可以发现从ng2请求ng1,是匹配DOCKER-ISOLATION-STAGE-1链路中的规则1(规则1匹配从docker1网卡出到非docker1网卡的所有请求),规则1又进入到DOCKER-ISOLATION-STAGE-2链,再查看DOCKER-ISOLATION-STAGE-2链中的规则2,规则2明确的写了任意来源ip,如果目标网卡是docker0,即全部执行DROP动作,丢弃所有请求,因为执行的是DROP动作,我们的请求没有收到明确的拒绝信息,而是一直等到请求超时(通过DOCKER-ISOLATION-STAGE-2规则2中的pkts列(7个包),确实是有包匹配到了当前规则并被DROP掉了)
-
验证分析
上面我分析出来了是DOCKER-ISOLATION-STAGE-2中关键的DROP规则实现了docker网桥网络间的隔离,我们可以通过删除这些规则恢复一下不同docker网桥网络之间的通信,从而进一步证明确实是这个规则阻拦的docker不同网桥间的通信
注:请务必不要在生产或者重要环境中,删除iptables规则做测试工作
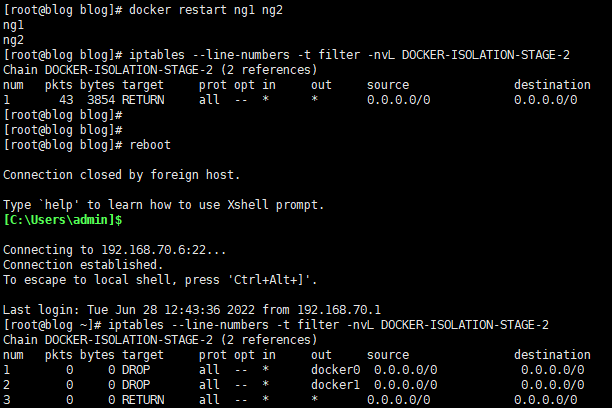
# 删除规则 # 在删除规则的过程中 # 这里我进入了一个思维误区 # 交互都是双向的所以我只删除拦截发请求的规则是有问题的 # 还需要把拦截返回请求的规则删除 # 可以看到下面的图中 # 我首先删除了规则2 进入容器ng2访问ng1没有成功 # 退出容器删除拦截返回的规则1后 再次访问成功了 # 即若保持网段的互通 需要将拦截请求和拦截返回的规则全部删除 iptables -t filter -D DOCKER-ISOLATION-STAGE-2 2 iptables -t filter -D DOCKER-ISOLATION-STAGE-2 1

-
谨慎操作iptables
由于iptables是属于内核层面的请求过滤,直接操作iptables是很有风险的,删除docker添加的iptables规则重启容器是不会恢复的,如果万幸你没有保存,就重启机器恢复吧
对iptables的任何手动调整,需要三思而后行
I sure hope you know what you are doing
总结
写了这么多,总之就是从不同的情况证明了iptables和docker-proxy在不同的情况各有个的作用
在写这篇文章之前,我看过一些博客的观点是 docker-proxy和iptables可以任选其一没必要共存,在亲身实践了之后,个人认为这两个是相辅相成的关系,是绝对不能彻底的一分为二的
当然在举例docker-proxy的作用时我用了一个非常简单的例子(自己访问自己)证明docker-proxy的必要性,但它的作用绝对不限于此,在和我运维朋友的测试中,启动一个比较复杂的应用jump server之后再kill了docker proxy后,jump server虽然能访问但是也不能正常的使用了(websocket链接异常)
如果你读懂了这篇文章,一定能感受docker的桥接网络设计是十分复杂的(iptables和docker-proxy协作完成网络交互),个人认为这种复杂的网络设计也可能是docker被k8s抛弃的其中一个原因吧